走进多核单片机内部世界
单核单片机的CPU可以通过数据总线和指令总线访问数据和指令,那么多核单片机如何去访问其他核变量的指令呢?如果两个核要同时访问另外一个核的变量又该如何处理呢?本文将以TC397为例来详细描述这些问题。1 访问变量 ...
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
| 单核单片机的CPU可以通过数据总线和指令总线访问数据和指令,那么多核单片机如何去访问其他核变量的指令呢?如果两个核要同时访问另外一个核的变量又该如何处理呢?本文将以TC397为例来详细描述这些问题。 1 访问变量 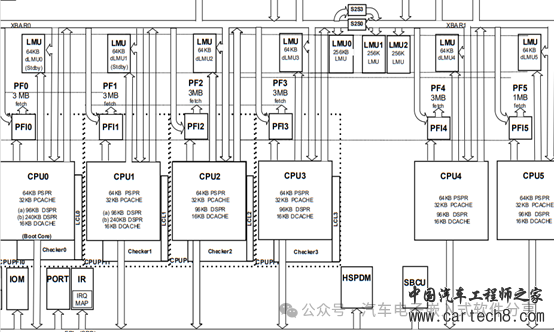 TC397的结构框图  单个CPU视角的视图 从图上可以看出每个CPU拥有自己内部总线(PFIx,x=0-5)可以访问的PFlash和内部的RAM(LMU)、DSPR(Data Scratchpad RAM,可以理解为存储数据的SRAM,比普通RAM访问速度更快)、PSPR(Program Scratchpad RAM,存储代码的RAM,CPU取指相对于普通的Flash更快),同时还可以通过XBAR(Cross Bar Interconnect,基于共享资源连接(SharedResource Interconnect)协议的内部信号连接)来访问其他CPU的LMU和PFlash,但是由于访问其他核时,会经过XBAR的转换,所以访问速度会变慢,因此尽量将本核访问的变量放于本核的LMU上。下边是访问和取指的速度对比表(单位为指令周期)。 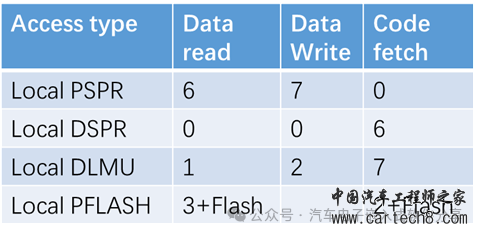 访问本地内存的速度 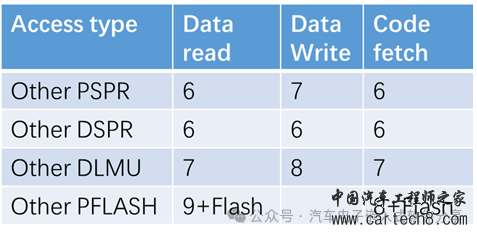 访问其他核的内存的速度 2 SRI(Shared Resource Interconnect)介绍 每个核的CPU可以访问其他核的变量,也可以被其他核访问,因此每个核的CPU都是既做SRI的master,又做SRI的slave,因此SRI的点对点的连接框图如下所示。 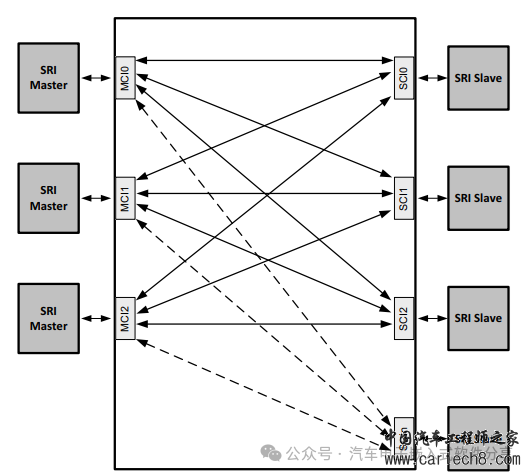 SRI crossbar点对点的连接框图 SRI的网络主要由访问数据的SRI master、被访问数据的SRI slaves和解决多个matser同时访问同一个slave的仲裁器(Arbiter)组成,如下图所示。 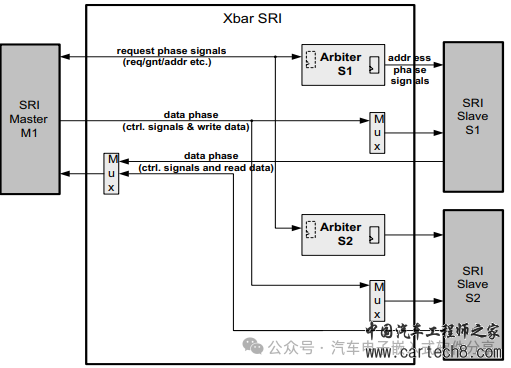 SRI的组成示意图 英飞凌TC397(TC1.6的内核架构)提供了一个类似于round-robin(轮询调度算法)的仲裁处理机制来确保每个主机的请求都可以被处理,为了提高实时性,采取了两个优先级的round-robin仲裁机制来确保高优先级的可以被优先处理,低优先级的请求在高优先级处理完后被请求。为了解决高优先级的请求一直占用,还增加了High Priority Round Share(HPRS,在高优先级的请求占用超过这个数值时,低优先级的请求就会被处理)。因此,对于一个高优先级的master的请求,其最大延迟为: HP_max_delay= number_of_high_priority_masters 对于一个低优先级的master的请求,其最大延迟为: LP_max_delay= ((HPRS+1) xnumber_of_low_priority_masters)-1 假如SRI从机的处理时间为10个clock,那么对于配置高优先级组有2个、低优先级组有6个且HPRS设置为7时,对于低优先级的master的请求的最大延迟为: LP_max_delay=( ((HPRS+1) xnumber_of_low_priority_masters)-1) x 10 clocks = ((7+1) x 6 - 1) x 10 = 470clocks. 对于默认配置(0高优先级,6低优先级)最大等待为6倍的反应周期。因此除了我们在<<一文搞懂AUTOSAR核间通信原理、实现和配置>>描述的跨核访问一个变量增加的spinlock导致CPU使用率下降外,即使多个CPU访问另一个CPU的不同变量,总线访问上也会增加延迟!。 |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论