智能驾驶-城市领航辅助必备的BEV以及Occupancy networks
智能驾驶-城市领航辅助必备的BEV以及Occupancy networks
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
| 最近马斯克到访国内,接待规格可谓不一般,其中到访了工信部讨论了“新能源汽车和智能网联汽车的发展”,这个信息,很多人猜测是为特斯拉的FSD落地国内进行铺路,国内也欢迎FSD智能驾驶鲶鱼效应,激活市场热情,助力国内智能驾驶的发展。 谈起智能驾驶,在Waymo和通用super cruise以及国内V2X风潮的带领下,国内智能驾驶开始选择的路径就是这条复杂但是更容易落地的高精地图+视觉识别的路线。但是,随着整车成本的压力,高精地图维护成本以及政策的问题,这条路线走到城市领航辅助就卡住了。 而特斯拉自始自终选择的是基于视觉的单车智能方案,他背后的逻辑是大数据+AI算法的方式,并且不断迭代算法,目前的算法是基于AI transformer的BEV(Bird-Eye-View Networks)以及occupancy networks,也是我之前文章《2023上海国际车展-智能电动4点观察》讲到国内各家走向趋同的路线。 所以本文将参考相关文章,极简的介绍下智能驾驶BEV(Bird-Eye-View Networks)以及occupancy networks算法和方案,以及国内各家的现状。 基于传统视觉智能驾驶算法的问题 智能驾驶如我之前文章《视觉为王-小鹏以及特斯拉的自动驾驶方案》介绍是当前智能驾驶依赖得主流,但是基于摄像头视觉的系统有很多缺陷,而且还有很多由于对象检测失败或其他问题引起的崩溃,这个在我之前文章《智能驾驶要用多少个激光雷达?分别放在哪里?什么作用?》也分析过。 一般摄像头算法是看到物体,然后匹配自己数据库里面标记的物体,但是如果摄像头看到不属于数据集中已经标定的对象,也就是遇到不认识的东西怎么办?所以这就是造成各种事故的根本原因。 另外在现实中,传统视觉算法: 
但在基于 LiDAR 激光雷达传感器系统中,由于激光雷达主动收发光所以他可以从物理上确定障碍物是否存在,确定了障碍物就可以保障不碰撞的安全。 那为什么特斯拉不用激光雷达? 激光雷达能够实现各种环境下的三维感知和定位功能,激光雷达通过发射激光束并创建点云地图来测量汽车与其周围环境之间的距离;该地图与摄像头视觉相结合,使车辆能够更准确地识别和理解其附近物体之间的空间关系;另外配合非常精确的高清 (HD) 地图来补充其车辆的感知系统,可以让汽车精确确定其位置和前方道路的布局。然而,这项技术的缺点,在2022年国内汽车市场成本压力和高精地图需要定期更新的挑战下体现得淋漓尽致。 其实马斯克的另一家公司 Space X 在激光雷达方面拥有丰富的知识和经验,他们甚至开发了自己的激光雷达并将其用于火箭。 所以特斯拉基于成本,更少约束和复杂度等原因的考虑下使用了基于视觉的occupancy networks占用神经网络算法。 Occupancy networks 占用网络是一种不同的算法,基于称为占用网格映射的机器人思想;其中包括将世界划分为一个网格单元,然后定义哪个单元格被占用,哪个单元格空闲。 占用网络的想法是获得体积占用。这意味着它是 3D 的。它使用“占用”而不是检测对比识别。而且是多视图。所以这就是它的样子:  他没有确切的去识别物体形状,而是给出一个近似值。同时他还可以在静态和动态对象之间进行预测。它的运行速度超过 100 FPS(一般相机的FPS是30也就是一秒钟拍摄30幅照片,所以它比相机所能产生的速度高出 3 倍),能达到10ms的运算能力,所以此算法对内存效率的要求比较高。 这个算法的三个核心是:
BEV是Andrej Karpathy在 Tesla AI Day 2020 上先介绍的,该算法展示了如何将检测到的物体、可行驶空间和其他物体放入 2D 鸟瞰图中。 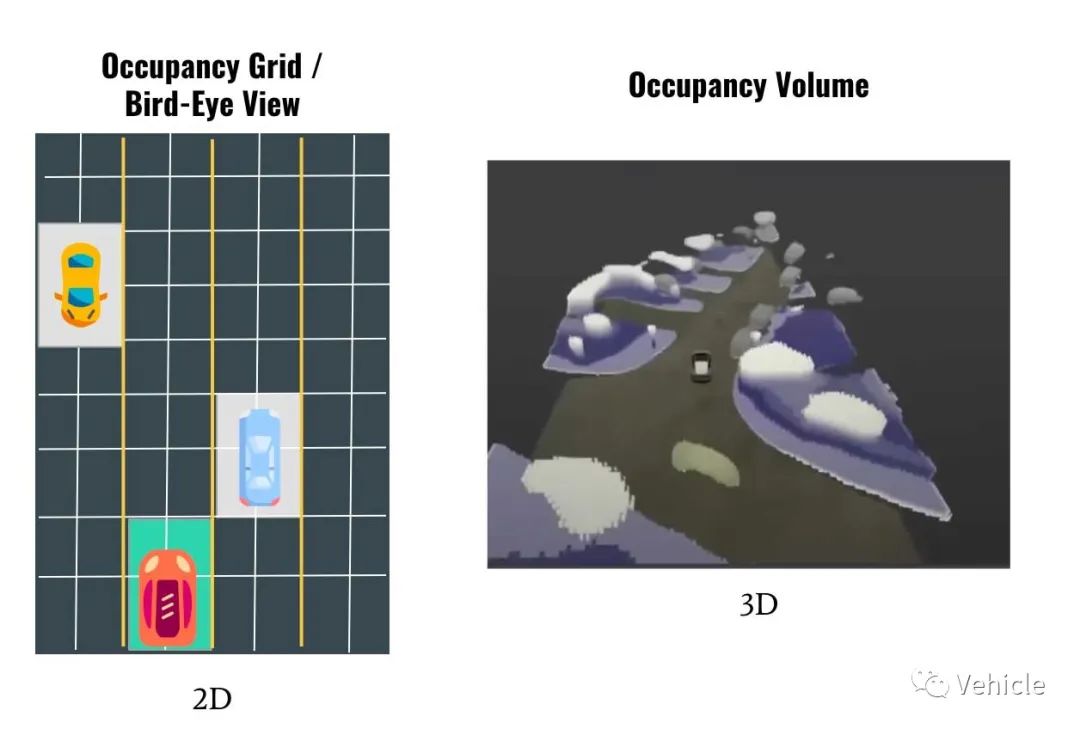 注意到主要区别了吗?一个是2D,另一个是3D。这给算法带来了第二个改进: 构建固定的立方体,一般的视觉算法是,尝试将检测到的物体与原有标定的数据联系,如果看到一辆卡车,将放置一个 7x3 的矩形,如果您看到一个行人,您将在您的占用网格中使用一个 1x1 的矩形。问题是,您无法预测各种非标准的悬垂类障碍物。 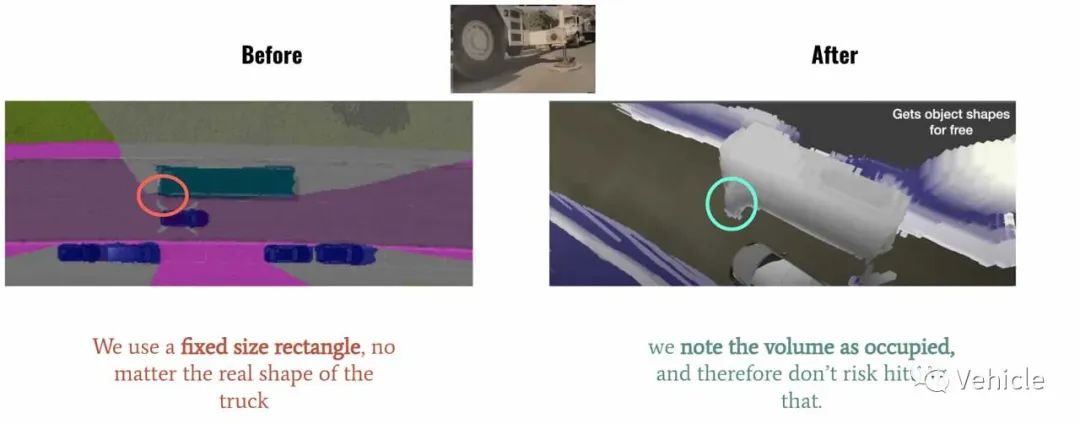 那怎么办?特斯拉occupancy networks采取的方式是:
 所以特斯拉occupancy networks算法,不去将识别物体分配到矩形中,而是去判断小立方里面是不是被占用。 那么特斯拉如何检测物体呢?视觉物体识别存在先天性的问题,它只能检测到他标定数据库里面被标定好的东西,通俗一点是他只能识别他认识(数据库里面标注过)的东西。 如果他看到他没有看过的东西,这就意味着他什么也没看到。  例如上图视觉算法由于不认识那个车厢,所以他压根就不显示,就表示没有看到。 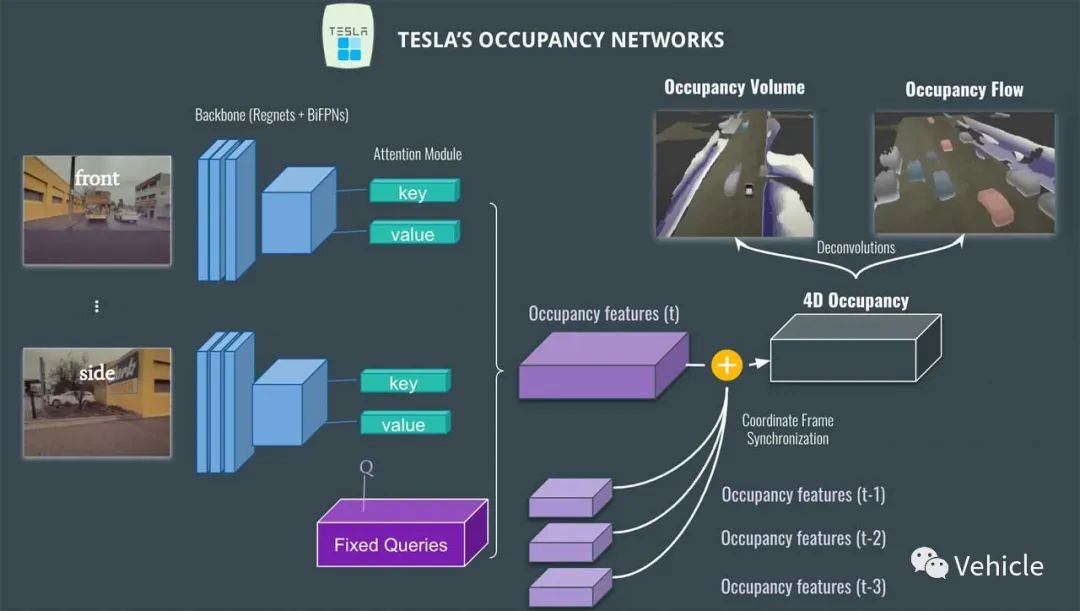 所以特斯拉采取整套方案是:
Occupancy Volume和Occupancy Flow就分别解决了3D世界中,长宽高以及时间的维度。 关于时间,特斯拉在这里实际做的是预测光流。在计算机视觉中,光流是像素从一帧移动到另一帧的量,有了每个体素的流动,因此有每辆车的运动;这对于遮挡非常有帮助,但对于预测、规划等其他问题也非常有用……  Occupancy Flow 实际上显示了每个对象的方向:红色:向前 - 蓝色:向后 - 灰色:静止等......(我们实际上有一个色轮代表每个可能的方向)。 以上就构成了特斯拉的Occupancy networks。 国内哪些厂商采用了BEV和Occupancy networks? 小鹏汽车,应该是最早喊出进军城区领航辅助的,最早使用激光雷达加30tops算力的P5应该是采用高精地图方案;到了今年G9上的XNGP,应该是开始了BEV算法。 上海车展期间
 所以BEV算法是2023年各个智能驾驶公司进军无高精地图城市领航辅助的发力重点,至于Occupancy networks,虽然很多人提到了,但国内智能驾驶公司估计BEV都还没有玩通,结果就被推着走向了Occupancy networks。高速领航辅助的时候基本上传统的摄像头识别加高精地图就能跑通,高配一点的可以配上激光雷达进行安全冗余;但是卷向城区,高精地图是个大问题,所以必须最少需要BEV算法作为环境地图的模拟,至于占位检测到底是通过视觉算法,还是激光雷达来做占位检测,不得而知。 那么Occupancy networks难点在哪里?我曾经听到过一个算法工程师表示,Occupancy networks等类似AI算法到github上随意download,可以获取非常多的算法,基本一两个算法工程师捣鼓几天就能搞出雏形。所以算法demo从来都不是难点,但Occupancy networks对高速内存以及环境方块化构建算力的要求,确是需要着重考虑。最后更重要的是数据训练集的大小。所以难的还是是整车或者功能的集成,算法的算力成本,算法运行环境等等,这也就是为什么智能驾驶创业demo的很多,能落地量产的才是王道。 总结 智能驾驶如果当他是一个Bussiness来看,基础的安全和驾驶便利性可以做成一个方案,实现高速领航也是一个方案,也就是我们常说指定ODD的智能驾驶有很多种方案,但是到了全场景的智能驾驶或许真的只有马斯克的类似于ChatGPT(ChatGPT以及其对汽车有什么影响?)大数据大模型的AI算法实现。 *未经准许严禁转载和摘录-获取参考资料方式:
|
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论