业内首篇!面向自动驾驶领域的NeRF应用综述
写在前面笔者的个人理解神经辐射场(NeRF)由于其固有的优势,特别是其隐含的表示和新颖的视图合成能力,引起了学术界和工业界的极大关注。随着深度学习的快速发展, ... ... ...
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
 写在前面&笔者的个人理解神经辐射场(NeRF)由于其固有的优势,特别是其隐含的表示和新颖的视图合成能力,引起了学术界和工业界的极大关注。随着深度学习的快速发展,出现了多种方法来探索NeRF在自动驾驶领域的潜在应用。然而,在当前的文献中,一个明显的空白是显而易见的。为了弥补这一差距,本文对NeRF在自动驾驶领域的应用进行了全面调查。我们的调查旨在对NeRF的自动驾驶应用进行分类,具体包括感知、3D重建、同时定位和建图(SLAM)以及仿真。我们深入分析并总结了每个应用类别的发现,最后就该领域的未来方向提供了见解和讨论。希望本文能为该领域的研究者提供一个全面的参考。据我们所知,这是第一次专门关注NeRF在自动驾驶领域的应用的调查。 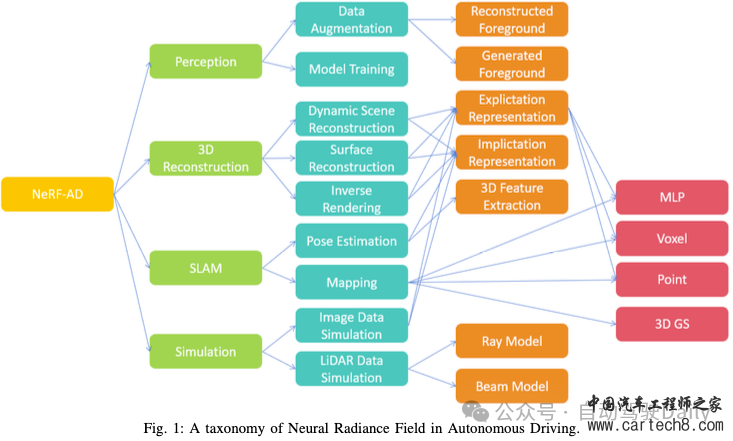 总结来说,本文的主要贡献如下:
感知NeRF在自动驾驶感知任务中表现出巨大的潜力,该任务分为两个分支:数据增强和模型训练。数据增强需要利用NeRF的新视图合成功能来对训练数据集进行真实感数据增强,而模型训练则需要将神经渲染集成到训练过程中,以捕捉几何细节并提高性能。本文描绘了这两个分支的管道,如图2所示。  Data Augmentation驾驶场景因其显著的多样性和复杂性而被广泛认可,由于长尾问题和高成本,无法捕捉所有场景。数据扩充是丰富训练数据集和提高模型性能的有效技术。各种研究利用图形引擎来合成训练数据,从而引入仿真到真实领域的差距。然而,NeRF在训练以近似真实图像时表现出较小的domain gap。 Drive-3DAug开创了基于相机的3D感知的3D数据增强研究的先河,并证明NeRF是实现这一目标的有效解决方案。传统的2D图像增强技术仅限于图像平面上的操作,如旋转和复制粘贴,与此不同,3D增强有可能显著提高模型性能,这在基于激光雷达的3D感知任务中已经得到了证实。如图3所示,Drive-3DAug包括两个阶段:初始训练阶段将场景分解为背景和前景,并使用NeRF构建3D模型,然后作为可重复使用的数字资产。随后的阶段包括将背景与操纵的前景相结合以创建新的驾驶场景,并利用体积渲染来生成增强图像。通过3D数据增强,与仅使用2D数据增强训练的模型相比,使用基于NeRF的增强训练的目标检测模型表现出优异的性能。 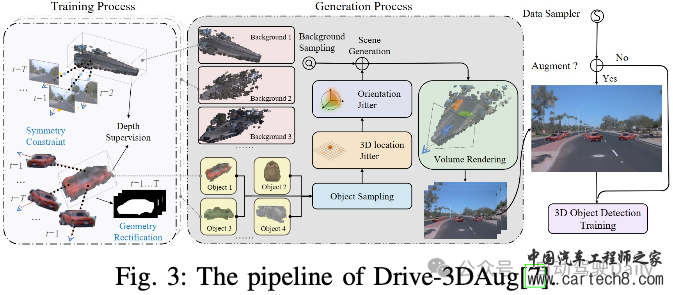 神经辐射场(NeRF)不仅使用收集的传感器数据,还使用生成模型合成的标签感知数据来重建场景,其具体目的是降低标注成本。Lift3D探索了生成对抗性网络(GAN)和神经辐射场(NeRF)的组合,旨在为3D感知任务生成数据。最初,使用预训练的StyleGAN2对具有姿势标签的图像进行密集采样。假设潜在代码控制的前8层构成姿势,而其余层影响形状和外观。来自ShapeNet的3D汽车模型用于获得来自不同视点的渲染汽车图像及其相应的姿态标签。随后,采用基于优化的GAN反演方法来找到前8层的对应模板潜伏层,将这些模板潜伏层与有意义的姿态信息相关联。然后,根据2D到3D流水线,将潜在姿势对合并到3D共享条件NeRF中。该过程消除了对2D上采样器的需要,如先前方法所要求的,并且能够合成任何分辨率的图像。最后,训练后的NeRF可以用于渲染增强图像,用于下游任务训练。 基于Lift3D,Adv3D提出了在NeRF背景下建模对抗性示例的创新探索,将原始感知采样和语义引导正则化与伪装对抗性纹理相结合,用于3D补丁攻击。他们的方法包括训练对抗性NeRF,以最大限度地降低3D检测器对训练集中周围目标的置信度,从而在各种姿势、场景和3D检测器中产生强大的泛化能力。此外,本文还介绍了一种针对这些攻击的防御机制,通过数据扩充采用对抗性训练。这项工作中展示的对抗性示例和3D建模的交叉表明了对3D感知系统的安全性和稳健性的潜在影响,为自动驾驶汽车、机器人和增强现实等应用提供了有价值的见解。 Model Training一些研究已经调查了NeRF用于数据增强的使用,但越来越多的研究将NeRF表示集成到模型中以提高性能。通过利用隐式场景表示和神经渲染,NeRF有效地弥合了3D场景和2D图像之间的差距,使其适用于各种3D感知任务。 NeRF在场景重建中表现出了非凡的性能,因此在与场景完成相关的感知任务中找到了自然的应用。BTS是最早在单视图重建中应用体渲染的公司之一。他们的方法包括将隐式密度场推断为有意义的几何场景表示,而不是仅仅依赖于深度预测,因为深度预测只能推断图像中的可见区域。它们利用编码器-解码器网络从输入图像中预测像素对齐的特征图。为了计算给定3D点的密度值,在3D点投影到图像上之后,从特征图中对特征进行双线性采样。随后,将该点的深度值和位置编码与特征一起输入到多层感知器(MLP)中,以预测密度。深度可以作为密度场的副产品生成,并且对于新颖的视图合成,颜色是从其他视图采样的,而不是由MLP预测的,因此大大降低了沿射线分布的复杂性,因为密度分布往往很简单。在训练过程中,除了输入视图之外,还会使用多个视图。这些观点分为两组,即Nloss和Nrender。从Nrender采样颜色,然后用于重建Nloss,其中重建视图和Nloss之间的光度一致性用作密度场的训练信号。这种训练策略有助于推理输入视图中的遮挡区域,前提是它们对其他视图可见。 如工作S4C中所研究的,遮挡区域的推理与语义场景完成高度相关。如图4所示,处理管道基于BTS,但包含了一个与密度字段并行的语义字段,从而能够渲染语义图。语义图和从现成的分割网络获得的伪真实标签之间的差异提供了额外的训练信号。由于从单一视角提供的监督只为观察到的区域提供训练信号,因此从战略上选择训练视角至关重要。因此,选择与输入视图具有随机偏移的侧向视图进行训练,从而增强多样性并提高预测质量,特别是对于更远的区域。 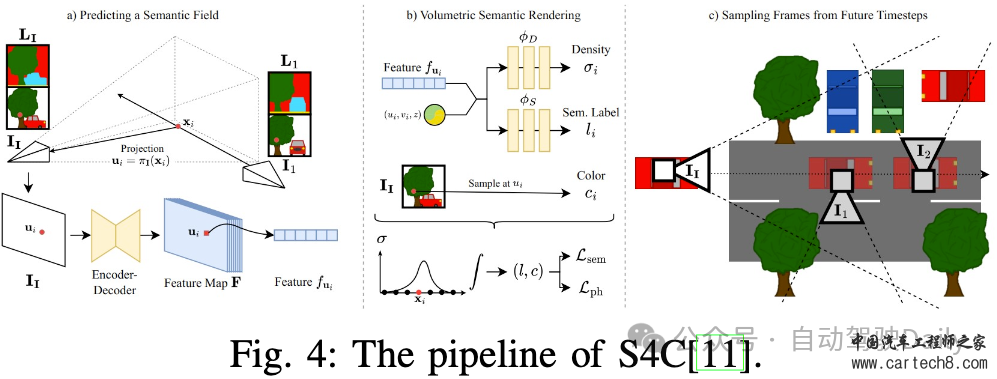 NeRF能够捕捉精确的几何形状,也可以应用于占用预测任务。SimpleOccupancy尝试了3D占用率估计,仅专注于几何估计,并将其与其他类似工作区分开来。它们利用共享主干来提取图像特征,然后以无参数的方式应用双线性插值来将这些特征提升到3D体积空间。3D卷积网络和位置嵌入被用于3D体积特征聚合。随后,通过应用Sigmoid函数来获得占用概率值。训练过程可以使用两种方式进行监督:一种是基于占用概率直接计算分类损失,而另一种是利用体绘制来获得深度图,并根据深度标签进行监督。结果表明,在各种度量中,深度损失优于分类损失,证明了体绘制的有效性。 UniOcc利用体积渲染来集成二维和三维表示监督。与之前的研究类似,该方法包括使用2D图像编码器、2D-3D视图转换器和3D编码器来生成3D体素特征,如图5所示。然而,与现有方法不同的是,UniOcc将占用转换为NeRF风格的表示,而不是直接使用占用头进行占用估计。它通过使用两个单独的MLP来预测体素的密度和语义logits来实现这一点。随后,基于密度和语义logits,应用几何和语义渲染技术来生成2D深度和语义logit,这可以由2D标签来监督。考虑到视点的稀疏性,在按语义类别过滤运动目标后,引入时间帧作为补充视点。由于建筑设计和各种优化技术,UniOcc在CVPR 2023 3D占用预测挑战赛中排名第三。 RenderOcc证明,3D占用标签不仅价格昂贵,而且由于占用注释的固有模糊性,还可能阻碍模型性能。这种限制限制了3D占用模型的可用性和可扩展性。因此,他们开创性地尝试仅使用2D标签来训练3D占用网络,并与3D标签监督的网络相比取得了有竞争力的性能。 NeRF模型也应用于MonoNeRD中的3D检测任务。利用场景几何来提高检测器的性能是一种常见的方法,深度估计在以前的工作中已经被广泛采用。然而,这往往会导致3D表示的稀疏性和显著的信息损失。在MonoNeRD中,类NeRF表示用于密集的3D几何体。首先,构造具有多个深度平面的相机截头体,以查询键值的方式提取图像特征。随后,两个卷积块将截头体特征转换为SDF和RGB特征,其中SDF特征可以进一步转换为密度特征。这些密度和RGB特征用于体积渲染,以使用深度损失和RGB损失来监督模型。由于不规则截头体特征不能直接由下游检测模块使用,因此通过从截头体的特征中进行三线性采样来构建3D体素特征,然后将其馈送到检测头。还应注意的是,其他视图可以用于渲染,只要它们的截头体与原始视图重叠即可。 除了特定的基于图像的任务外,体积渲染还有可能弥合点云和图像之间的差距,促进预训练的表示学习。在他们的工作中,PRED专注于激光雷达点云的预训练。如图6所示,作者首先将逐点掩蔽应用于输入点云,即使在稀疏区域中也保留了目标的语义。然后,通过编码器将剩余的点云转换为鸟瞰图(BEV)特征图,随后通过解码器将其建图为符号距离函数(SDF)和语义信息。由于点云中没有颜色信息,体积渲染后只使用语义和深度监督。通过利用语义渲染,图像的全面信息和丰富语义增强了点云预训练在各种任务中的性能。 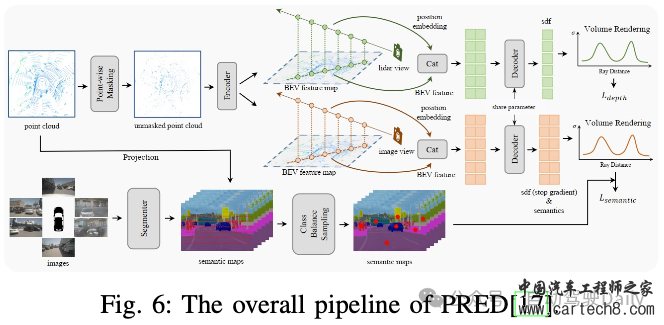 UniPAD更进一步,提出了一种灵活的预训练方法,可以无缝集成到2D和3D框架中。该方法包括两个组件:特定于模态的编码器和体积渲染解码器。对于点云数据,3D主干用于特征提取,而对于多视图图像数据,2D主干用于提取图像特征,随后将图像特征转换为3D体素表示。遵循MAE的方法,采用掩蔽策略输入数据以有效地学习表示。然后将体素特征转换为带符号距离函数(SDF)值和颜色值。通过积分预测的颜色和沿射线的采样深度,图像和深度图由groundtruth渲染和监督。为了降低内存成本,引入了深度感知光线采样,仅对深度阈值内的光线进行采样,从而忽略远处的背景。 3D RECONSTRUCTION如表一所示,我们将三维重建分为三个子问题:动态场景重建、曲面重建和逆渲染。我们将在以下部分进行讨论。 1)动态场景重建:神经场景图(NSG)首次提出用通过变换矩阵连接的神经场景图来重建3D动态场景。每个节点按动态节点和静态节点进行分类。动态节点可以是每个时间戳中由3D边界框标注的任何动态参与者(汽车和行人)。静态节点被公式化为静态背景。每个节点由类别共享MLP和每个实例的可学习嵌入表示。在光线投射过程中,NSG首先通过在每个节点的3D框中执行AABB光线相交算法来解开每个节点,然后要求MLP处理每个归一化坐标。最后,以深度顺序的合成方式进行体绘制。这些场景图表示能够以统一的方式从新的目标插入、修改、移除和渲染新视角。  随着激光雷达的增强,神经点光场使用激光雷达点云作为初始化,并学习光场来重建驾驶场景。进行体积渲染时,该方法会为每条射线从点云中选择一组K个最近的点。然后,它利用光场函数来预测光线的颜色,考虑光线的方向和通过多头注意力模块从最近点聚集的特征。 在不依赖于GT 3D框或深度估计和光流的预训练模型的情况下,EmerNeRF以一种自我惊讶的方式学习动态场。它首先学习一个流场,该流场向前和向后扭曲到下一帧或上一帧,然后聚合每点特征。为了增强语义场景理解的实用性,EmerNeRF建议结合2D基础模型特征,如DINOv2特征,以利于NeRF的训练。 2)表面重建:FEGR学习使用3D场景的混合表示对驾驶场景进行内部分解。给定姿势图像,FEGR首先使用哈希网格学习显式网格,然后通过其提出的混合延迟渲染管道估计底层场景的空间变化材料和HDR照明。它们在诸如重新照明和虚拟目标插入之类的下游应用程序上显示出令人满意的结果。 StreetSurf开发了一种使用哈希表的街道视图多视图隐式表面重建方法。他们根据与相机的距离,将大规模和多尺度的驾驶场景分解为三个不同的部分:近景、远景和天空部分。对于每个部分,他们都使用了不同的模型——近距离场景的长方体NeuS模型、远视的超长方体NeRF++模型和天空的定向MLP模型。此外,他们还结合了单目估计深度和法线,为重建过程提供进一步的监督。 为了进一步提取详细的几何图形,DNMP建议使用网格基元对整个场景进行参数化。对整个场景进行体素化,并为每个体素分配一个网络,以参数化局部区域的几何结构和辐射。从预训练的潜在空间中解码DNMP的形状,以约束鲁棒形状优化的自由度。辐射特征与DNMP的每个网格顶点相关联,用于辐射信息编码。 3)逆渲染:UrbanIR学习从驾驶场景的单个视频中推断形状、反照率和能见度。它提出了一个可见性损失函数,有助于在原始场景中进行高精度的阴影体积估计。这允许精确的编辑控制,最终从任何视点提供重新照明场景和无缝插入目标的照片级真实感渲染。 LightSim是一个神经照明相机仿真系统,能够生成多样化、逼真和可控的数据。LightSim首先根据传感器数据按比例构建具有照明感知能力的数字双胞胎,并将场景分解为具有精确几何结构、外观和估计场景照明的动态演员和静态背景。然后,LightSim结合基于物理和可学习的延迟渲染,对修改后的场景进行逼真的重新照明,例如更改太阳位置和阴影,或更改太阳亮度,生成空间和时间一致的相机视频。 4)其他:MINE学习用于新颖视图合成的可推广的多平面图像特征网格。PVG、DrivingGaussian和Street Gaussians使用3D Gaussian Splatting重建动态驾驶场景,显示高质量的重建和实时渲染。  SLAM由于NeRF基于姿势和视角方向渲染图像的强大能力,许多研究人员自然会考虑和研究将NeRF与姿态估计以及SLAM相结合的尝试。相关研究通常可分为两类:NeRF的姿态估计和NeRF的场景表示。 Pose Estimation by NeRF最近出现了几种利用NeRF估计实时姿态的具体方法,可分为三维隐式表示和三维特征提取。  1)三维隐式表示:最直接的想法是利用NeRF的三维隐式表达能力进行重新定位。考虑到NeRF的流水线,iNeRF提出了一个“反向”流水线,通过预训练的NeRF来优化姿态估计,如图9所示。NeRF根据估计的姿态生成渲染像素,然后通过在渲染像素和观察像素之间反向传播残差来优化该姿态。NeRF Navigation进一步将基于动态模型的过程损失与光度损失相结合,以过滤跟踪结果并避免姿态初始化。除了直接将观察到的图像与渲染的图像进行比较外,NeRF VINS还将观察到图像与NeRF从与当前估计姿势具有小偏移的姿势生成的图像进行匹配,以更新姿势估计。作者声称,合成图像应该与观测图像具有显著的重叠视场(FOV),这有利于匹配和姿态估计。 2)3D特征提取:然而,上述方法都需要在场景中训练有素的NeRF。一些研究人员认为NeRF是适用于不同场景的通用3D特征提取器。NeRF-Loc设计了一个可推广的NeRF,该NeRF仅以几个支持的图像和深度为条件,以从采样的3D点生成3D描述符。从查询图像中提取2D描述符以获得3D-2D对应关系,并通过PnP(Perspective-n-Point)以从粗到细的方式估计相对姿态。同时,Nerfels也注意到了NeRF的3D表示能力。Nerfels没有将模型过度拟合到整个场景,而是使用可渲染代码表示与场景无关的局部3D补丁,从而提高了可推广性。在Nerfels中进行了联合PnP+光度优化,从而改进了手工制作和学习的局部特征的宽基线姿态估计。 Scene representation by NeRF与NeRF优化姿态估计相反,NeRF在SLAM中的另一个应用是表示整个场景以优化建图性能。基于场景表示级别,我们将相关研究分为MLP级别、体素级别、点级别和3D高斯级别的表示。 1)MLP-level:最初在iMAP中探索了NeRF在SLAM中优化建图性能的想法,该想法建立了并行跟踪和建图过程,共享一个MLP作为场景表示,并具有相同的损失。跟踪过程优化了相对于固定场景网络的姿态,与iNeRF的管道类似。而在建图过程中,经过基于信息增益的关键帧选择和渲染丢失引导的主动采样,可以反向传播整个可微框架,共同优化跟踪和建图性能。iMODE进一步实现了无需深度输入的大规模增量建图。为了提取更详细的特征,李等人提出了一种多MLP神经隐式编码结构 2)Voxel-level:Instant NGP源于传统的基于MLP的NeRF,将场景编码为多分辨率散列体素顶点以实现实时重建,这启发了一组基于NeRF的SLAM研究,以在体素水平上表示场景。在Orbeez SLAM中提出了初始方法,该方法基于经典单目SLAM算法的姿态估计和关键帧选择结果,将即时NGP应用于密集建图中。NGEL-SLAM的后续研究包括闭环和全局束调整(BA),用于全局姿态精化。然而,上述研究基本上只是将ORB-SLAM2等成熟的SLAM系统集成到NeRF框架中,在NeRF本身没有表现出显著的内在创新。 3)Point-level:基于神经点云的场景表示也有望实现大规模实时跟踪和建图,因为点云的结构不像网格那样紧凑,适合动态分配。Point SLAM执行该策略,并根据输入RGBD图像的信息密度动态调整锚点密度,以不同的点密度呈现不同级别的细节,从而在跟踪和建图方面实现与其他密集神经RGBD SLAM方法相比具有竞争力的结果。 由于基于点云的表示比MLP或体素更轻,更适合于闭环和全局姿态图优化,CP-SLAM利用神经点云的优势,促进了单智能体的闭环和多智能体的协同定位和建图的多智能体SLAM系统。类似地,Loopy SLAM设计了迭代增长的点云子建图,以执行循环闭合并减少错误累积。PIN-SLAM还结合了基于点的隐式神经表示,以通过激光雷达实现大规模SLAM。 4)3D Gaussian-level:随着近年来3D GS的快速发展,大量的三维高斯水平SLAM正在出现。第一组这种类型的SLAM集成了显式3D高斯表示,以提高跟踪和建图性能,这得益于快速飞溅渲染技术。最近,SemGauss SLAM和SGS-SLAM进一步结合语义信息来指导束调整,并为下游任务构建语义图。 仿真自动驾驶仿真通过为传感器数据生成创建逼真的虚拟环境,为真实世界的测试提供了一种更安全、更具成本效益的替代方案,这有助于创建各种驾驶场景,并降低安全风险。传统的仿真方法,如CARLA和AirSim,依赖于手动场景创建,由于手工制作的资产和简化的物理,仿真与真实的差距很大,面临着局限性。GeoSim试图通过结合图形和神经网络生成视频场景来弥补这一差距,但未能仿真新视图的传感器数据。神经辐射场方法显著增强了真实感,减少了场景创建和编辑的手动工作量,为缩小真实世界和虚拟世界之间的领域差距提供了一个很有前途的解决方案。仿真方法主要分为两类:图像数据仿真和激光雷达数据仿真。我们将在以下部分讨论它们。 Image Data Simulation当前基于神经辐射场的自动驾驶图像数据仿真方法包括通过使用来自真实驾驶环境的一系列图像以及相应的相机姿态来重建场景,从而允许修改原始场景中的车辆行为,以生成和渲染新的照片真实感图像。根据表示技术的不同,这些方法进一步分为以NeRF为例的隐式表示方法和以3D GS为例的显式表示方法。 1)隐式表示:这些方法利用类似于NeRF的隐式表示模型来重建场景。NSG采用普通的NeRF模型来表示静态背景。对于车辆重建,NSG使用NeRF模型重建同一类别的车辆,为每辆车分配一个潜在的外观重建代码。训练后,NSG可以通过控制车辆的3D边界框、生成新场景并最终渲染照片级真实感图像来编辑场景中车辆的姿势。NSG通过使用3D边界框将场景分解为静态背景和车辆,将复杂的动态场景任务转换为多个独立静态目标的3D重建。受普通NeRF模型能力的限制,NSG的训练时间长,渲染质量差。Instant NGP通过使用多级哈希网格编码,提高了场景重建的效率和图像渲染质量。UniSim采用NSG的场景分解方法,使用单独的Instant NGP模型分别重建静态背景和车辆,如图11所示。为了进一步提高背景重建的效率,UniSim利用激光雷达观测的几何先验来识别近表面体素,并仅优化其特征。在处理场景中的车辆时,UniSim使用超网络从可学习的潜在车辆中生成每个车辆的表示。UniSim采用闭环评估来证明其仿真数据可用于测试自动驾驶汽车在安全关键场景中的性能(图12)。 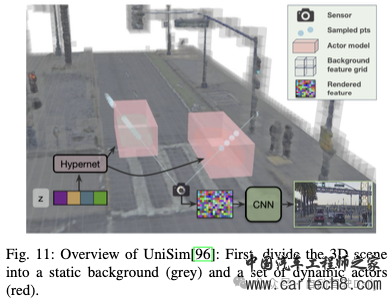  2)显式表示:由于频繁使用MLP来查询场景中的点信息,它们的训练和渲染时间无法满足实时性要求。三维高斯散射(3DGS)可以在满足实时三维重建要求的同时生成高质量的新视点图像和场景几何结构,使基于3DGS的自动驾驶仿真方法越来越流行。DrivingGaussian使用LiDAR点云数据初始化3D高斯的位置,并与其他方法类似,使用3D边界框将场景的3D高斯分解为场景内的静态背景和车辆,如图13所示。为了将3DGS应用于大规模静态背景,DrivingGaussian通过引入增量静态3D高斯来增强3DGS,通过将背景分解为多个独立的小仓来重建完整的静态背景,并依次初始化每个仓中3D高斯的位置。Driving高斯使用nuScenes数据集提供的3D边界框作为所有车辆的真实位置,但在实际应用中,需要跟踪器模型来预测图像中车辆的3D边界盒。然而,跟踪器模型生成的边界框通常是有噪声的。直接使用它们来优化场景表示会导致渲染质量下降。为了解决这个问题,Street Gaussians通过向每辆车的变换矩阵添加可学习变换,将跟踪姿态视为可学习参数。与其他基于3DGS的方法不同,Street Gaussians采用4D球面谐波(4D SH)模型来重建动态车的颜色。这使得车辆能够展现出随时间变化的外观。Street Gaussians还通过监督学习为空间中的每个3D高斯分配一个语义参数,帮助模型理解3D场景。此外,为了实现对3D场景的整体理解,HUGS除了预测场景的RGB图像和语义信息外,还预测场景的光流信息。 LiDAR Data Simulation激光雷达数据仿真的目的是利用激光雷达测量数据来增强神经场景表示,从而促进从新视角合成逼真的激光雷达扫描。基于不同的激光雷达传感过程建模技术,这些方法主要分为两类:射线模型和光束模型。下文将分别介绍这两种方法。 1)射线模型:这些方法将激光雷达的传感过程简化为单一射线,取代了原始NeRF模型中的相机射线,并通过球面投影将激光雷达点云数据转换为360度全景图像作为地面实况,将点云数据转化为伪图像数据。NeRF LiDAR使用具有语义标签的LiDAR点云数据作为基本事实,通过神经辐射场重建3D场景,并生成具有准确语义标签的激光雷达点云。为了准确再现激光雷达光线下降现象,NeRF激光雷达通过在全景图像上训练分类掩模来预测这种现象发生的位置。虽然NeRF-LiDAR可以生成具有语义信息的LiDAR点云数据,但它不能预测射线强度的重要数据。激光雷达NeRF还将激光雷达点云数据转换为全景图像,并生成每个伪像素处的距离、强度和光线下降概率的3D表示。类NeRF方法在大规模场景的低纹理区域中显示较差的几何体。为了克服这一限制,激光雷达NeRF结合了结构正则化来保留局部结构细节,从而提高了NeRF更有效地重建几何形状的能力。 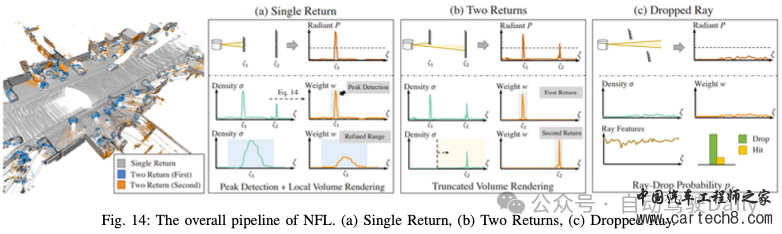 2)光束模型:与上述方法不同,NFL使用具有散射角的发散光束来仿真激光雷达传感过程。这项技术可以准确地再现关键的传感器行为,如光束发散、二次返回和光线下降,如图14所示。  讨论感知在数据分支的背景下,NeRF因其潜在的应用而备受关注。虽然神经辐射场(NeRF)已被探索用于生成单帧图像,但这种方法被证明不适用于依赖于多帧输入的算法。包括BEVFormer和Sparse4D系列在内的各种研究都展示了整合时间信息的有效性。迫切需要探索NeRF解锁时间一致性数据增强的能力。 在模型分支的背景下,NeRF利用隐式场景表示和神经渲染将3D场景与2D图像连接起来,展示了不同感知任务的进步。然而,神经渲染过程的计算效率低下,在保持多视图和时间一致性的同时,特别是在自动驾驶等高动态场景中,对有效采样光线提出了挑战。 重建在重建领域,一些应用已被用于解决工业问题,例如将在一个传感器设置中收集的数据转换为另一个传感器设备(主要是相机的内外参),以适应新车,并创建用于增强和评估的新数据。然而,大多数方法仅限于重建刚性动态场景,例如只有移动车辆的静态街道,而不能处理步行行人等非刚性动态目标。未来的工作可以在重建目标之前合并更多的目标。同时,重建质量和运行时间仍然可能是当前方法的限制。未来的工作可以利用可推广的先验知识,如NeRFusion来加快重建。 此外,潜在的改进可以利用Generative AI的最新进展,生成无限量的数据,而不仅仅限于重建真实世界的数据。例如,研究人员可以使用OpenAI的Sora首先生成逼真的视频,然后将其重建为3D表示,以实现多样化的3D生成。 SLAM现有的基于NeRF的SLAM研究具有自动驾驶定位和建图的能力。此外,GT自动标记和在线外参标定是基于NeRF的SLAM研究的两个潜在领域。 然而,目前的研究主要集中在室内场景上,尽管这些技术可以在自动驾驶中参考,但仍然无法处理室外大规模场景。此外,自动驾驶中的动态特性极大地影响了传统的基于NeRF的SLAM研究,因为它们往往受到时变场景的影响。为了使基于NeRF的SLAM能够用于自动驾驶,迫切需要一种更轻量级的数据结构,用于在大规模场景中进行建图。此外,减少动态目标影响的策略也是必要的。 另一个不可忽略的因素是光照条件。在自动驾驶中,许多场景都包含严重的光线条件,如夜间或雪雾等异常天气。如何在这些场景中提高基于NeRF的SLAM的鲁棒性是一个巨大的挑战。一种可能的解决方案是引入诸如雷达之类的鲁棒传感器作为补充。 仿真当前基于神经辐射场的模拟技术依赖于从多个视角捕捉的大量图像,以在重建广阔的城市场景时实现更准确的几何恢复。NeRF和3D高斯飞溅技术都不能精确恢复视觉盲点内的场景,主要是由于这些模型在场景重建过程中泛化能力不足,无法从有限的稀疏视点数据中恢复完整的整体场景。因此,未来的工作将需要基于少镜头视图合成的方法来解决具有有限视图的场景的精确重建问题。 其次,车辆外观和场景照明之间缺乏逼真的交互式反馈,导致渲染图像的真实性受损。现有的方法将车辆和场景重建为独立的元素,从而忽略了场景照明对车辆外观的影响。未来,目标的外观编辑可以与传统的计算机图形着色算法集成。 此外,通过现有方法重建的目标是刚性的,它们的几何形状不会随着时间的推移而改变,这使得在重建整个场景的同时重建和编辑行人等可变形目标成为一个挑战。在下一阶段的研究中,可能会结合现有的可变形人体模型重建方法,实现行人的重建和编辑能力。  结论在这项调查中,我们对自动驾驶背景下的神经辐射场进行了全面的回顾。具体来说,我们首先介绍了NeRF的基本原理和背景,然后深入分析了NeRF在AD各个领域的应用,分为感知、三维重建、SLAM和仿真。最后,我们讨论了每一类中剩余的挑战,并提供了可能的解决方案。我们希望这项调查将有助于未来的研究工作,推动自动驾驶时代的到来。 - End - |


文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论