复杂环境下的车道线识别算法改进分析(二):如何解决散点识别和车道线拟合 ...
通过前文Canny算法中调整阈值的介绍,我们可以看到,即使识别出足够多的车道线上的边缘点,仍然存在两个问题:一是如何识别属于哪些散点。车道线以及哪些散点是无用的噪声点;二是如何将属于车道线的边缘点拟合成直 ...
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
| 过前文Canny算法中调整阈值的介绍,我们可以看到,即使识别出足够多的车道线上的边缘点,仍然存在两个问题:一是如何识别属于哪些散点。车道线以及哪些散点是无用的噪声点;二是如何将属于车道线的边缘点拟合成直线或曲线。 本文将接续前文内容,继续讲解如何解决散点识别和车道线拟合这两个问题。 基于车道线宽度的边缘散点识别道线算法 为了解决这两个问题,需要将摄像头采集的原始图像中的ROI区域转化为鸟瞰图,然后通过基于车道线宽度的特征点筛选方法提取车道线的边缘点,最后得到车道线的边缘点。 1、车道线特征点的选择与提取 该方法利用了车道宽度基本相同的特点,一般的鸟瞰图中宽度为0.25米的车道线宽度为4~5个像素,且车道线内部是一个连通的区域。将相机采集的图像转化为鸟瞰图后,采用Canny算法进行处理,初步得到包含边缘点和噪声点的二值图像。然后,通过逐行扫描的方法对二值图像进行滤波,提取属于车道线的边缘点,丢弃其余点,以减少干扰噪声点对曲线拟合的影响。 车道线特征点提取的详细步骤如下: 步骤1:从图像底部开始逐行扫描二值图像。如果检测到某行像素点的灰度值全为0,则继续扫描上一行像素点,否则转步骤2。 步骤2:记录第一个灰度值为255的像素点的列号n,并继续扫描下一个像素点。若第n列第4或第5个像素点的灰度值仍为255,则记录该点的列号m,并执行步骤3;否则,将第一个灰度值为255的像素点视为干扰点,将其值设置为零然后继续扫描,然后重复步骤2。 步骤3:继续检测上一行n列和m列像素点的灰度值。若灰度值为255,则重复步骤3;否则,检测相邻列像素点的灰度值,如果为255,则重复步骤3;否则,将步骤二中距离为4或5个像素的两个像素点确定为干扰点,并将其值设置为0。继续步骤2,从该行的下一个像素开始扫描。 步骤4:扫描完各行各列的像素点后,设置同一行灰度值为255~255的两个像素点之间的所有像素点的最终灰度值。 上述流程如图7所示: 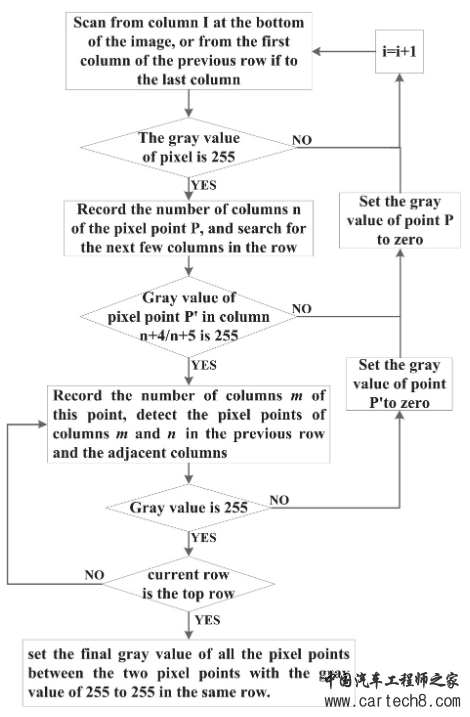 下图显示了以上这种基于车道线宽度算法逐行扫描后的车道线提取结果。  可以看到,该算法在尽可能减少干扰点数量的情况下提取了足够的车道线边缘点,逐行扫描方法基本上成功地从所有像素点中提取出属于车道线的边缘点。另外,可以看出,质量较差的车道虚线符合本文设计的提取规则,也可以被很好的提取。 基于RANSAC的特征点曲线拟合 图像预处理后,多条车道线上存在散点。需要对这些散点进行拟合,找到一条可以包含足够多散点的曲线,即一条可以包含足够多散点的曲线。本文采用RANSAC对特征点进行拟合,形成最适合车道线的曲线。有学者在研究中使用canny方法作为比较对象,得到了较差的车道线检测结果。除了它对Canny算法缺乏改进之外,另一个重要原因是它使用了最小二乘法而不是RANSAC。最小二乘法就是从所有的点中找出最合适的曲线。这种不放弃的方法会导致所有噪声点都被考虑在内,因此不适合与Canny算法一起使用。RANSAC是一种非确定性算法,它会在一定的概率下产生合理的结果,这允许更多的迭代来增加其概率。操作流程如下: 第一步:假设模型是一个三阶曲线方程,随机选取3个样本点来拟合模型: 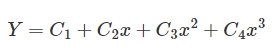 第二步:假设公差范围为 z,找出距离拟合曲线公差范围内的点,并统计点数。 第三步:再次随机选择3个点,重复第一步到第二步的操作,直至迭代结束。 总之,每次拟合后,在公差范围内都有相应的数据点。找出满足设定置信度的数据点数量就是最终的拟合结果。本文通过设置置信度条件来确定最大迭代次数。步骤1-3的迭代次数与模型的异常值比例以及我们需要的置信度有关。可以用以下公式表示: 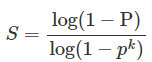 其中 S 是所需测试的最小数量,P是置信水平,p是内点百分比,k是随机样本数量。具体的置信水平需要通过反复测试并综合考虑准确性和实时性来确定。 在上述算法不同场景下进行了验证,并在原始图像上标注了最终的车道线,并选取了一些有代表性的截图如下图所示。图(a)为正常光照区域,(b)为光照不均匀区域,(c)为大阴影区域,(d)为线条干扰区域,(e)为高亮度区域。  基于逆透视投影变换的特征点拟合 传统算法中,通过基于RANSAC算法的贝塞尔曲线拟合算法对边缘点进行拟合,可以得到识别的车道线。然而这种RANSAC算法拟合是通过直接逐行扫描图像,利用宽度匹配来确定哪些散点属于车道线的。该方法没有考虑摄像头获取的图像中车道线可能不是垂直的情况,图像中存在一定的角度的倾斜,所以需要逆透视变换或者距离变换,为后续车道线特征点的选择和提取做好准备。 为了解决以上问题,可以利用逆透视变换算法可以将发生几何变形的平面图像变换为无畸变的俯视图。目前实现逆透视变换的方法主要有两种: 第一种是通过相机标定方法获得相机的内参数和外参数,变换公式由内参数矩阵和外参数矩阵根据相机的成像模型,最后通过计算得到逆透视变换后的俯视图。该方法虽然可以校正相机的畸变,但涉及参数和变量较多,算法复杂,运算时间长。 第二种方法是推导透视原理的几何关系,利用简化的逆透视变换公式进行计算,从而得到图像的俯视图。这种方法适用于畸变较小的小角度相机。 考虑到现有相机的特点和实时性,从简化算法和实现功能的角度出发,推荐选择对第一种逆透视变换方法进行一定程度的简化。 由于现有的逆透视技术已经比较成熟,本文不再讨论其推导过程,整体改造如下: 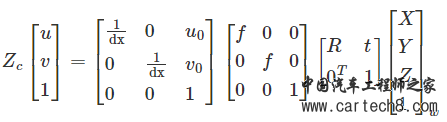 其中旋转矩阵R是3*3的矩阵,t是偏移量。从后到前,中间三个矩阵分别是相机与世界坐标变换矩阵、投影关系矩阵和像素相平面关系矩阵。 由于智能车的车载摄像头安装在车辆内部时通常是固定俯仰角和侧倾角的,因此可以简化为上述类型。如果相机安装仔细,不相对Z轴旋转,并考虑到地平线实际上是水平的,道路所在平面取ZW=0,上式可进一步简化如下: 其中,ZC为透视投影系数,M1为相机内参矩阵,由相机内参fx、fy、u0、v0确定;M2是相机的外参矩阵,其中R和T是由相机位置决定的坐标变换矩阵。 根据上述原理,可以找到图像平面中的点与世界坐标系中的点的一一对应关系,然后将其转化为鸟瞰图。 需要说明的是,由于远处像素数量较少,转换为鸟瞰图时需要进行大量的插值和拟合计算。在远离传感器的区域进行鸟瞰图的变换不仅消耗计算能力,而且无法提供清晰的车道线。因此,如果针对低速无人驾驶汽车而言,仅对ROI区域进行变换(对于同一相机,ROI区域的像素坐标固定),最终使车道线的两条边平行,使得进一步的分析变得更加容易。逆透视投影变换得到的近距离车道线还是比较精准的还原。而针对高速情况下需要考虑探测到更远距离的车道线,而视觉感知能识别到的车道线散点往往较少,同时考虑到计算的实时性要求也更高,因此很难做到高速情况下利用单纯的逆透视投影变换还原车道线信息。 我们知道后续BEV鸟瞰图的基础算法也是这样多个摄像头作为图像源投影到3D空间后进行匹配拼接而得出全景的,可以说这种拼接过程也就是一种简化版的三维重建。那么,如果是远距离情况下的散点而言,点数显然不够多,投影到3D空间中用于点云重建的点就很有限了,这就意味着很难在其空间中通过拼接重现真实世界场景中的车道线,亦或者重建的车道线质量也无法满足检测要求。 当然,有条件的感知算法供应商为了弥补这样的缺陷往往采用两种比较典型的方法进行: 1、大量真值系统注入 实际就是一种Mono 3D的真值训练法。提前通过激光+摄像头的方式做数据闭环进行全场景采样,得到了真实环境下的各种车道线采样场景数据,然后通过人工标注的方式进行场景标注,这样一套标注值可以提前写入到真值系统中。当后续运行对应的感知识别算法时,只需要在进行图像预处理后输入对应的真值系统做图像Match就可以很直观的得出对应的车道线真值了。 当然,1中所提到的方案不是在每个算法供应商都能采用的,其一是这样的真值系统需要采集大量的环境真值数据,这需要大量的车队来运行采集过程。且不谈是否合规的问题,就是这样庞大的车队容量也不是一般公司能够承受的。那么,此时也有一些追求性价比的算法供应商会采用第二种方法:单V加BEV融合的算法策略。 2、单V加BEV的融合策略 其实,简单点说就是视觉感知的大融合技术。即考虑到大小眼摄像头的小眼睛能识别到更远距离的车道信息,大眼睛能识别到更宽的车道信息,先各自分别跑各自的神经网络算法,得到对应的环境感知输出。其次,该大小眼仍然参与整车全视角下的BEV构建,通过上述所提到的逆透视投影变换得到对应的BEV鸟瞰图。最后,将前两者的感知模块通过变换到同一个坐标系下进行融合生成对应的三维感知结果将更加准确的还原实际场景。 这里需要注意的是,考虑到计算资源和效率,由于智能汽车更关注自车道前方的车道线信息,因此,对于单V识别,考虑前视大小眼就足够弥补BEV在远距离感知中的缺陷了。当然不差钱的Tier1或主机厂,如果选择了较大算力平台的域控,也可以分别将侧视和后视进行单独深度学习生成对应的感知结果。 总结 本文接续前文介绍了利用车道宽度这一显着特征来提取满足该特征的边缘点,最终利用RANSAC特征点拟合的方法得到识别的车道线。多个代表性场景的实验结果表明,该方法对复杂光照条件具有较强的适应性,能够在高反光、暗影、照度不均等区域识别视场内的路径像素。因此,在正常道路和特殊环境下基本不会出现识别失败的情况。  |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论