Key值更新随机Hash锁对RFID安全隐私的加强
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
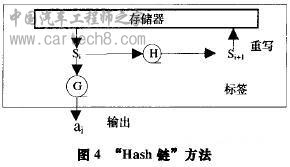
在该方法中,标签每次回答是随机的,因此可以防止依据特定输出而进行的位置跟踪攻击。但是,该方法也有一定的缺陷:(1)阅读器需要搜索所有标签ID,并为每一个标签计算Hash(IDkIIR),因此标签数目很多时,系统延时会很长,效率并不高;(2)随机Hash锁不具备前向安全性,若敌人获得了标签ID值,则可根据R值计算出Hash(IDIIR)值,因此可追踪到标签历史位置信息。 2.2.3 Hash链(Hash Chain)[4] NTT实验室提出了一个Hash链方法,其保证了前向安全性,工作机制如下:锁定标签:对于标签ID,阅读器随机选取一个数Sl发送给标签,并将(ID,S )存储到后台数据库中,标签存储接收
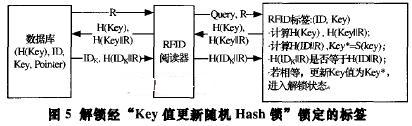
到Sl后,进入锁定状态。 解锁标签:在第i次事务交换中,阅读器向标签发出询问消息,标签回答ai=G(S。),并更新Si+l=H(s。),其中G和H为单向Hash函数,如图4所示。 阅读器接收到ai后,搜索数据库中所有的(ID,S1)数据对,并为每个标签计算 ai =G(H (s1)),比较ai*是否等于ai,若相等,则返回相应ID。 方法优点:具有不可分辨性,因为G是单向Hash函数,外人获得a。值不能推算出S。值,当外人观察标签输出时,G输出的是随机数,所以不能将a。和a。+l联系起来;具有前向安全性,因为H是单向Hash函数,即使窃取了Si+1值,也无法推算出S 值,所以无法获得标签历史活动信息。 方法缺点:需要为每一个标签计算ai*:G(H (s1)),假设数据库中存储的标签个数为N,则需进行N个记录搜索,2N个Hash函数计算,N次比较,计算和比较量较大,不适合标签数目较多的情况。 3 Key值更新随机Hash锁 鉴于上述几种安全隐私保护方法存在的缺陷,并结合几种方法的思想,本文提出了一种“Key值更新随机Hash锁”方法,实现了安全高效的读取访问控制。 3.1工作原理 数据库记录主要包括4列:H(Key),ID,Key,Pointer,主键为H(Key)。其中ID为标签唯一标志号,Key是阅读器为每个标签选取的随机关键字,H(Key)是Key的单向Hash函数H计算值,Pointer是数据记录关联指针,主要用来保证数据的一致性[5]。 下面详细阐述该方法的基本工作原理: (1)锁定标签 对于标签ID,首先阅读器随机选取一个数作为该标签的Key,将Key值发送给该标签,并建立标签在数据库中的初始记录(H(Key),ID,Key,0)),标签将接收到的Key值存储下来后,进入锁定状态。 (2)解锁标签 1)数据库首先产生一个随机数R,传送给阅读器,然后阅读器将询问消息Query和R都发送给标签; 2)标签根据接收到的R和自身Key值,计算H(Key)和H(KeylIR)的值,然后将(H(Key),H(KeylIR))数据对发送给阅读器,接着自行计算H(IDIIR)和Key =S(key),但此时Key值并不更新。 3)阅读器查找数据库中的记录, 若找到记录i: (H(Keyi),IDk,Key。,Pointeri),其中H(Key。):H(Key),则数据库计算H(KeyjIIR),并比较H(Key ItR)与接收到的H(KeyIIR)值是否相等。若不相等,则忽略此消息,表明标签是非法标签,在此阅读器完成对标签的合法性验证;若相等则继续下一步; 4)数据库计算H(IDkIIR)的值,并将IDk和H(IDkIIR)的值都传送给阅读器。然后阅读器将H(IDkIIR)发送给标签; 5)数据库计算Key*i=S(key。)和H(Key* )的值。若Pointeri:O, 则在数据库中添加新的记录J:(H(Key*i),IDbKey i,i),并将记录i修改成(H(Key。),IDbKeyij); 若Pointer !=O, 则找到第Pointer。条记录, 将其修改成(H(Key i),IDk,Key i,i); 6)在标签接收到H(IDkIIR)后,比较其与标签在第2步中计算的H(IDIIR)是否相等,若相等,则将自身的Key值更新为Key ,标签进入解锁状态,对阅读器开放其所有功能;若不相等,表明阅读器是非法阅读器,标签保持沉默,在此标签完成对阅读器的验证。如图5所示。
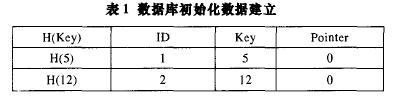
3.2数值实验 设数据库初始时存储了两个标签,ID分别为1、2,随机选择的Key分别为5、12,数据库初始化如表1所示。
|
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论