全面盘点 | 一文看尽Occupancy
全面盘点 | 一文看尽Occupancy
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
prologue照老样子先说为什么会写这篇文章,因为到目前我的分割大模型对实际部署的小模型并没有帮助。这让我有点郁闷,更郁闷的是后面蒸馏的环节目前也不是我在做。卡不够我的大的模型还在训,等训完想自己上手搞一搞蒸馏,我还就不信了学不好!所以这段时间就写一写看过的paper了,看Bev的时候occupancy相关的有些文章也顺便看了,写一写挺好的。 ok,那第一个,为什么自动驾驶感知都已经有bev了,然后又出来了occupancy Nerwork? 这是2022年特斯拉提出来的一个"技术?",但我记得昊哥有说过这个学术概念最早是他和一些大佬提出来的。occupancy和bev最主要的区别就是,bev是二维的呈现形式把所有的结果在高度上拍扁了,而occupancy则是三维的,空间上的。那他的好处显而易见,他可以表达存在在空中的东西以及空间中的状态 。拿一个场景来举例,比如大家在小区的车位上会有一个地锁。或者高速收费站停车场的抬杆,这个地锁或者杆子如果你从bev的视角去看由于没有高度信息地锁关闭和打开看起来是一样的。但如果是传统2D的检测或者occupancy这样可以看到3D空间的占用状态,这样的是可以检出来的。不管怎么说,occupancy相比原来的bounding box,细粒度更高,更加能够表达物体的细节了,这些细节则代表了更多的corner case可以被解决。 下面拿雷总的图来举个例子,该图来自2023年12月28日小米技术发布会  原本的占用网格像“我的世界”一样,使用一个一个的小立方体来代表物体,立方体越小,物体的分辨率就越高,越吃算力。小米这次出的超分矢量算法感觉怎么有点像场景补全,看起来输出的结果像是mesh拟合了物体,但没有很精细还是有很多空洞。这应该是做的语义场景补全当然这样并非首创,特斯拉在前段时间也有放出泊车视频,也是这样的形式但更加精细和连贯。 第二个,为什么这个文章叫“一文看尽occupancy”,当然我们不可能一文看尽,paper如滚滚长江东流水,一浪更比一浪强。主要是噱头,哈哈哈,有些地方如果有问题大家一定指出来发评论。 第三个在share paper之前还是说一些题外话,占用网格理论上可以说Bev的升级版,把占用网格切换到鸟瞰图的视角下就可以当bev来用。关于bev之前已经有写过文章讲 其道大光:万字长文谈自动驾驶bev感知(一) blog.csdn.net/weixin_46214675/article/details/135101143?spm=1001.2014.3001.5502 大家感兴趣可以看一下。对于bev和occupancy,这两个东西并不是完全割裂的,许多bev检测的算法也都在支持occ task,比如我们之前介绍过的bevdet,方法叫BEVDet4D-Occ还是啥  再有就是Semantic Scene Completion 与 occupancy,因为占用网格之前都是一个一个带语义的小方块,所以有个任务和他很相似叫做语义场景补全在semantic kitti上有个task,他的真值是对激光雷达数据的逐点标注,把他体素化后就可以拿来做occupancy的预测。现在的占用网格真值大家一般也都是这样搞起来的,当然nuscenes也可以。但这两个task还是不太一样的,3D Semantic Scene Completion更关注于从稀疏的输入数据中恢复出完整的3D场景的几何和语义信息,而Occupancy则更侧重于通过体素网格来表示和理解3D空间的占用情况。  之前我也有想过和同学一起搞一下占用网格,但是太耗资源了根本搞不起来,**能搞得起占用网格的都是大户人家(ps 这是重点!!!)**。在自动驾驶里面小公司是根本搞不起的,大多数公司还在追bev的方案,其实跑通真正量产了的不多,占用网络应该是厂家下一个要追赶的技术点了。 My partial paper listVision-based occupancy :1. MonoScene: Monocular 3D Semantic Scene Completion [CVPR 2022]https://arxiv.org/pdf/2112.00726.pdf arxiv.org/pdf/2112.00726.pdf
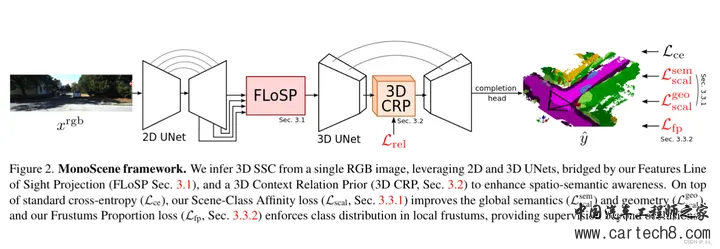 对着上面的图通俗易懂的简单说一下,一个图像进来,过2D UNET,flosp(Features Line of Sight Projection),再过3d unet,3D UNET中间插入了一个3D CRP(3D Context Relation Prior)模块,然后做语义补全任务。 最核心的是FLOSP模块,如何将2D特征提升到3D? 其实就是从不同尺度下3D投影到2D,拿到多个尺度采样特征后混合相加完了给后面的3D Unet,就是这样。这个操作和lss一样后面我们也会见到。 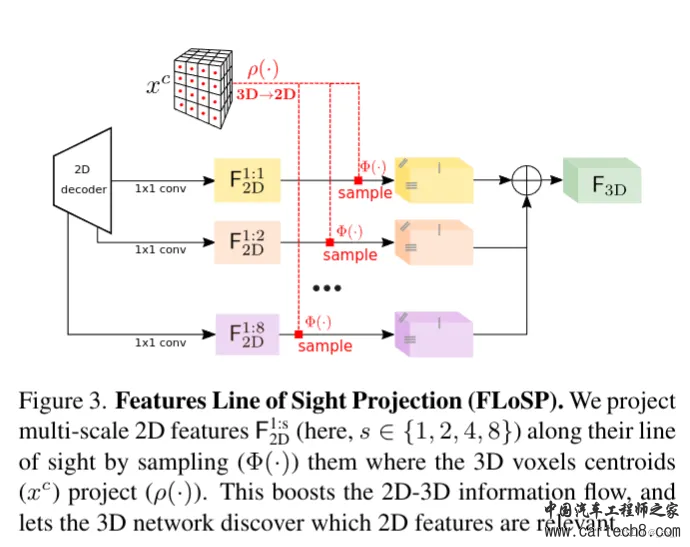 剩下的3D Context Relation Prior也不细说,关系矩阵和超体素特征点乘也算是一种算注意力了,超体素是用来建模体素空间关系的。后面的Loss设计部分大家也可以看一看的。 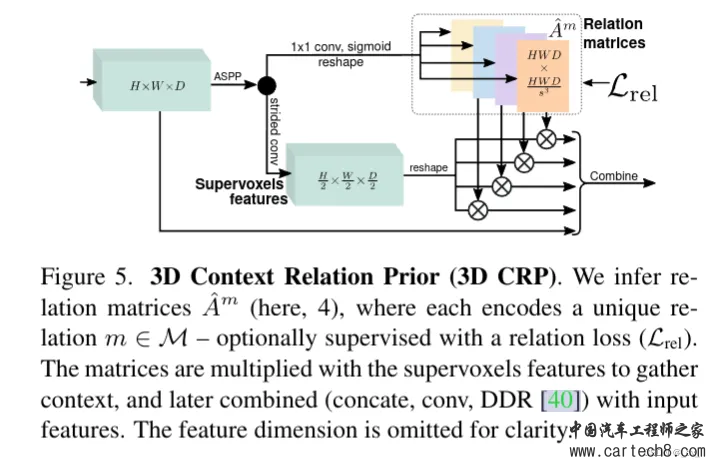 2. Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction [CVPR 2023]https://arxiv.org/pdf/2302.07817.pdf arxiv.org/pdf/2302.07817.pdf
 
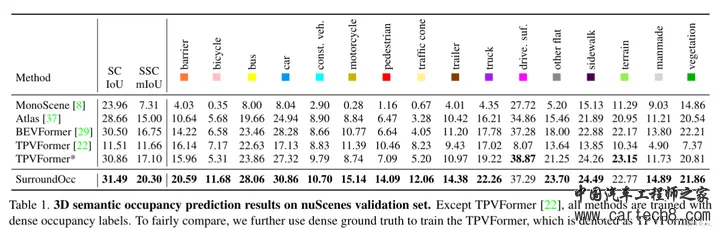
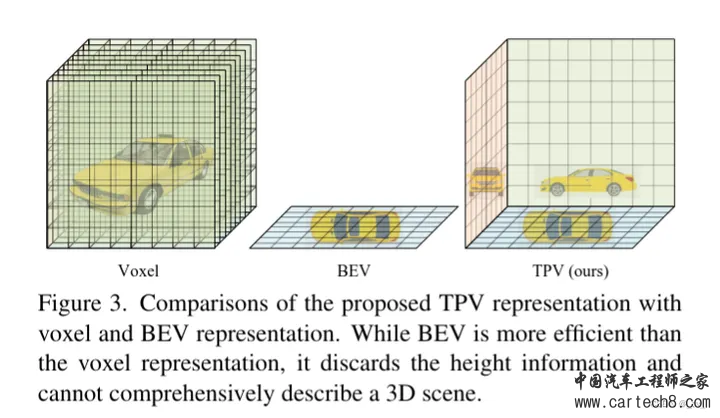 复杂的就不讲了,看paper里面的公式,1是体素表达xyz,2是bev表达xy,3 4 5 是三视图表达xy、zx、yz。S是sampling,V,B,T都是features。 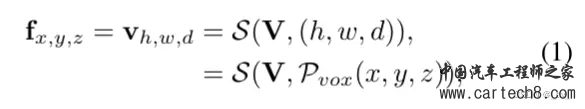 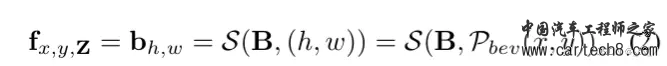 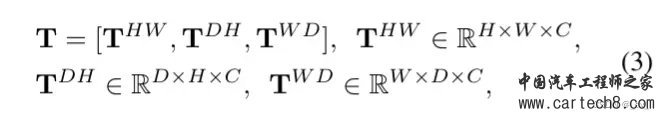 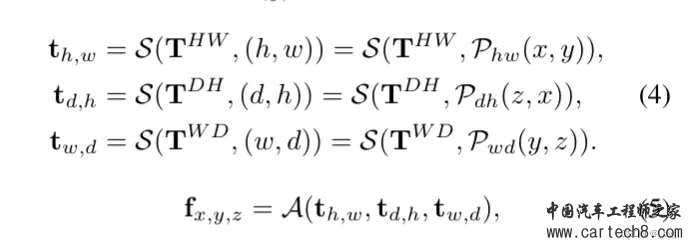 整体流程: 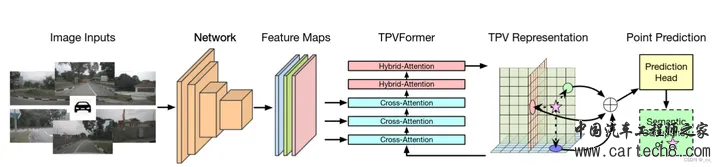 至于网络特征怎么提取,transformer怎么做注意力大家可以看文章,后面有时间应该会对文章有更细致的讲解,核心思想就是我的特征是从三个视图拿到的加起来,然后去做prediction。就是这样。 然后给大家share一下对比结果: 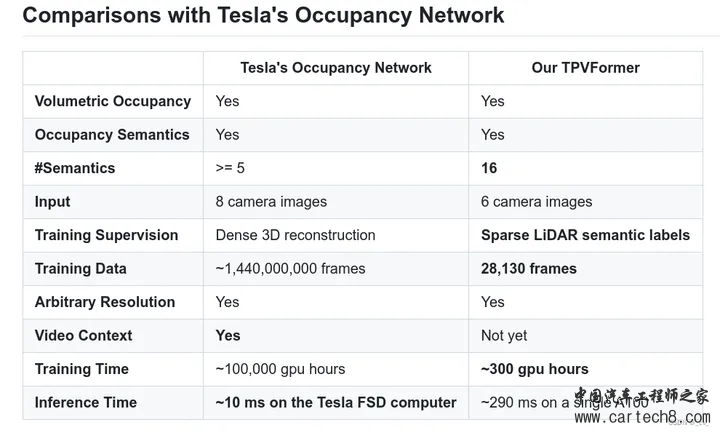 3. SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving [ICCV 2023]https://arxiv.org/pdf/2303.09551.pdf arxiv.org/pdf/2303.09551.pdf
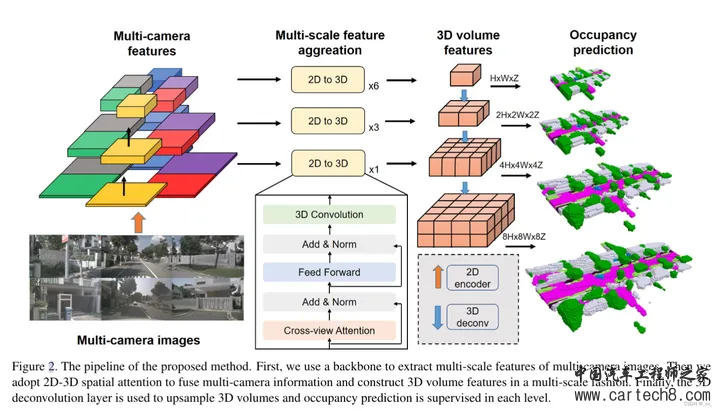
2D-3D Spatial Attention:就是把2d特征转到3d空间下的模块。首先3D体积查询定义为Q∈RC×H×W ×Z,这个Q就是3D reference point,然后对于每个Q,会根据给定的内外参将其对应的 3D 点投影到 2D 视图(就是虚线箭头部分)。然后只使用 3D 参考点命中的点,在这些投影的 2D 位置周围采样 2D 特征(怎么采样就是下面的DeformAttn,Qp查询是3D 参考点,P(qp,i )是2D采样,X是camera feature)。模块输出 F ∈ RC×H×W ×Z 是根据可变形注意机制的采样特征的加权和。公式化如下: 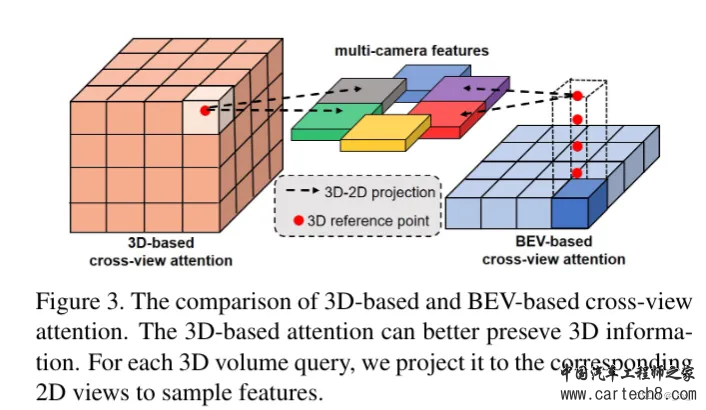 都看到这里了那就再说一下他这个bev-based cross-view attention是怎么个意思也很容易,大家都知道bev是没高度的,而XY是确定的,所以一般会在bev的Z轴上采样出几个固定的高度来,拿到坐标的XYZ之后再投影到图像上。 
 至于Multi-scale Occupancy Prediction这个部分上面其实已经说过了,下面就是公式化,Deconv就是反卷积拿来做上采样,这算个小知识点,大家不熟悉的可以了解一下。  总结说一下,上面提到的只是关键点,其实还有很多细节的部分是没有提到的!!! 4. OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction [ICCV 2023]https://arxiv.org/pdf/2304.05316.pdf arxiv.org/pdf/2304.05316.pdf 
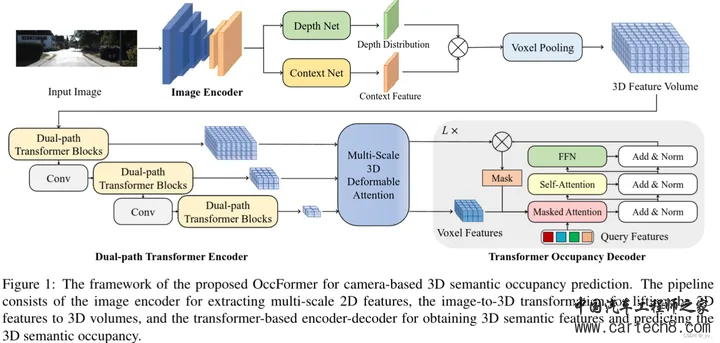
blog.csdn.net/weixin_46214675/article/details/135101143?spm=1001.2014.3001.5501 下面的我们看重点看几个
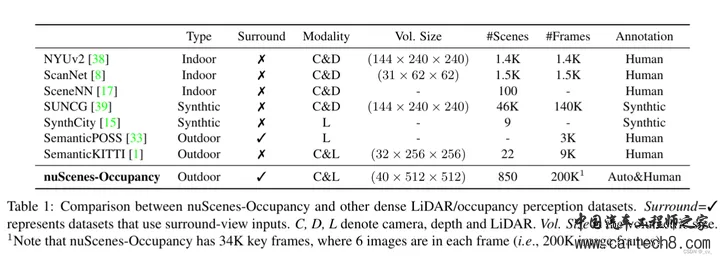
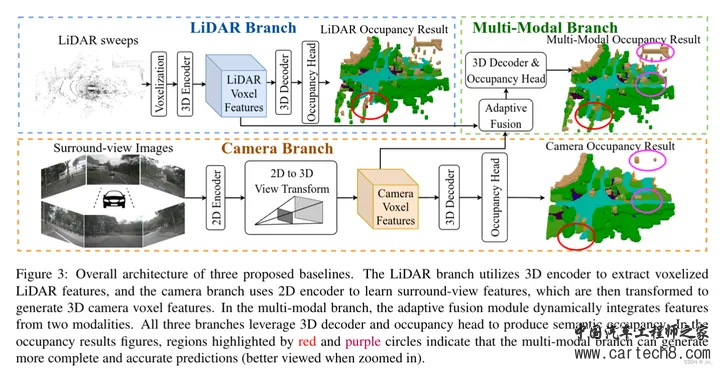
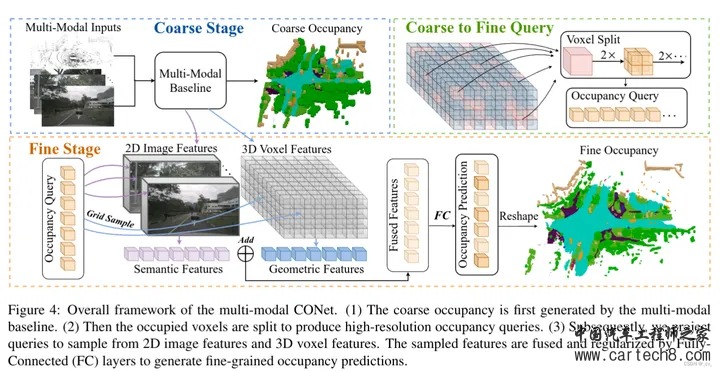
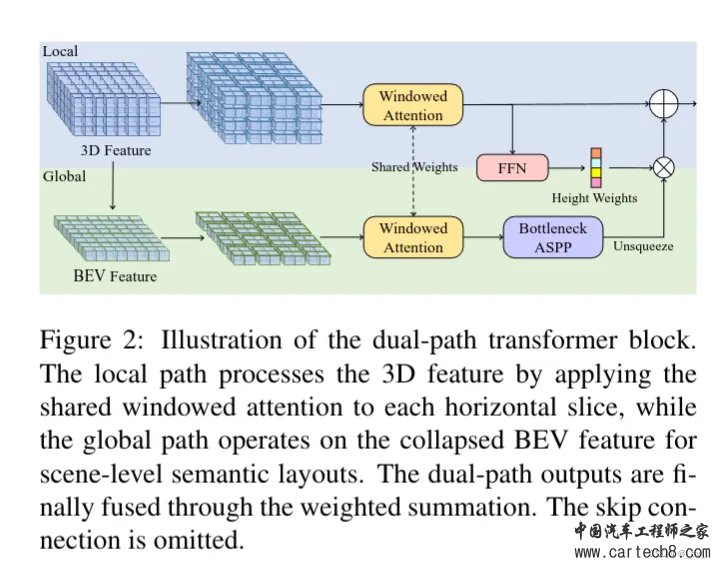 这里的局部细粒度细节和全局路径的场景级布局是怎么搞的呢? local path 主要是提取细粒度语义结构。水平方向包含了最多的变化,所以用一个共享编码器,来并行处理所有 BEV 切片,同时保留大部分语义信息。具体来说,我们将高度维度合并到批次维度(batch dimension)中,并采用 windowed self-attention 作为局部特征提取器可以动态地关注具有适度计算的远程区域。(这里的窗口自注意力就是在一个固定范围内算自注意力,如果大家不了解注意力机制,这不行,这得了解,后面看什么时候我把去年做的transformer PPT放出来)global path 的目的是有效地捕捉场景级的语义布局 ,首先通过沿高度维度的平均池化来获得BEV特征,利用来自 local path 的相同的windowed self-attention 来处理相邻语义的BEV特征。由于发现 BEV 平面上的 global self-attention 会消耗过多的内存,因此采用ASPP来捕捉全局的语义。公式化输出如下 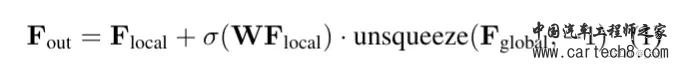 中间的Multi-Scale3DDeformableAttention就不说了,见过很多次了无非就是2D变3D用到三线性特征采样trilinear feature sampling。接下来说一下Transformer Occupancy Decoder ,就是transformer 的decoder,这一层特征加上上一层的特征,确实没啥好说的。至于里面提出的Preserve-Pooling就是个max-pooling也没啥特别只是用的比较好;Class-Guided Sampling就是添加类别权重的超参,看起来高大上罢了。   到这里就可以开始讲一讲 Interesting thing  这是在[Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction, CVPR 2023]( https://github.com/wzzheng/TPVFormer github.com/wzzheng/TPVFormer ),github官方的代码仓库贴出来的信息,一般来说后出来的paper效果都应该好一些,但大家看下面两个表格,上面的是前面讲过的surroundOcc(ICCV 2023),下面是我们这篇文章的OccFormer(iccv2023)。好像后面发出来occformer还要差一些,同时也没和自己的工作surroundOcc对比(不过应该那时候surroundOcc还没中所以) 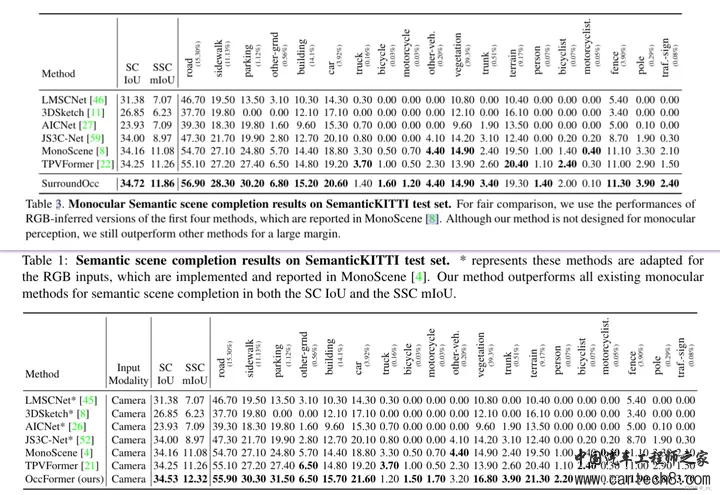 5. OpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perceptionhttps://arxiv.org/pdf/2303.03991.pdf arxiv.org/pdf/2303.03991.pdf
“
  “
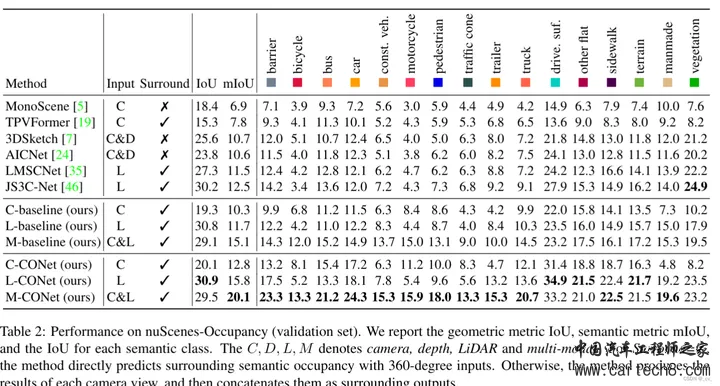 下一篇! 6. VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion [CVPR 2023 Highlight]https://arxiv.org/pdf/2302.12251.pdf arxiv.org/pdf/2302.12251.pdf 
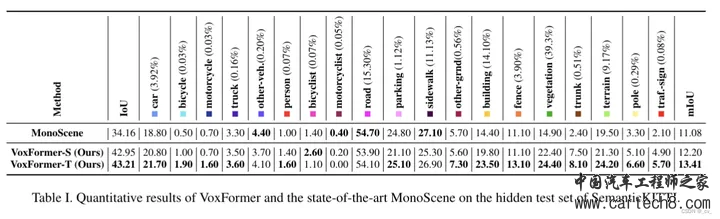
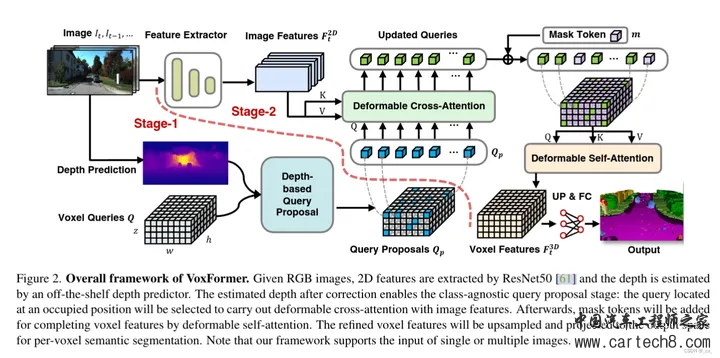 image序列过来后会先进行Depth Prediction,这里是直接利用现成的深度估计模型,如单眼深度或立体深度估计,直接预测每个图像像素(u, v)的深度Z(u, v)。之后,深度图 Z 将反投影到 3D 点云中,但由此产生的3D点云质量较低,特别是在远程区域。(因为地平线的深度非常不一致;只有少数像素决定了大区域的深度)。 Depth Prediction 下面有个Voxel Queries Q,预定义的体素查询为 3D 网格形可学习参数 ,Q ∈R h×w×z×d 其中 h × w × z 的空间分辨率低于输出分辨率 H × W × Z 。 接着Depth Prediction 和Voxel Queries Q被送到Depth-based Query Proposal。这里有一个点,为了获得好的Q,使用模型 Θocc 以较低空间分辨率预测占用图来帮助校正图像深度。具体来说,首先将合成点云转换为二值体素网格映射图M(in),如果至少占用一个点,每个体素被标记为1。然后我们可以通过 M(out) = Θocc(Min) 预测占用率,其中 M(out) ∈ {0, 1}h×w×z 的分辨率低于输入 M(in) ∈ {0, 1}H×W ×Z,因为较低的分辨率对深度误差更稳健并与体素查询的分辨率兼容。简单来说就是低分辨率更鲁棒。现在就可以来proposal Q了,Q是怎么出呢?! 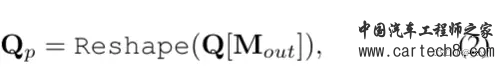 Q从上面的低分辨率预测占用图来选,这样的话通过删除许多空白空间和保存计算和内存,再者通过减少错误 2D 到 3D 对应关系引起的歧义来简化注意力学习。 到这里就完成了第一个阶段的Class-Agnostic Query Proposal,接下来就是第二个阶段Class-Specific Segmentation.ResNet-50 backbone来 提取 2D features ,然后2D 的Feature作为k,v,有了第一阶段的Q,就可以做注意力了。Deformable Cross-Attention 老熟人了,2d 3d版本也都有了。  经过几层可变形交叉注意后,Q将被更新。然后我们再接着看就能看到Mask Token了,这就是类似于掩码自动编码器(MAE)的3D场景补全了。在前面虽然选择了一些体素查询来处理图像;剩余的体素将与另一个可学习的参数关联起来补全3D体素特征。为了简洁起见将这种可学习的参数命名为mask token,因为没被选择的Q,就类似于从Q中被屏蔽掉了。具体来说,每个mask token是一个可学习的向量,表示存在一个待预测的缺失体素,位置嵌入也被添加。MAE也是如此,重建mask掉的token。 输入的token有了,接下来就是算Deformbale Self-Attention,获得refined voxel features。   在往后就是上采样和全连接,输出预测结果。 
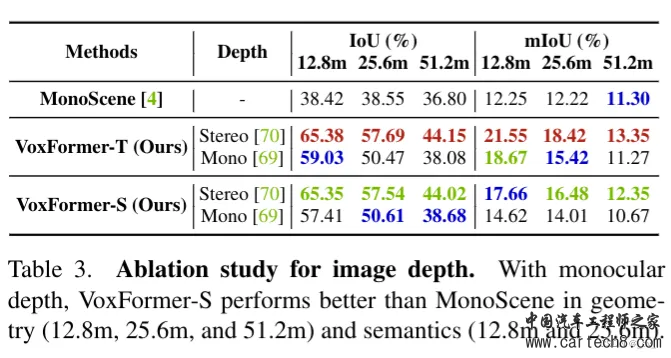 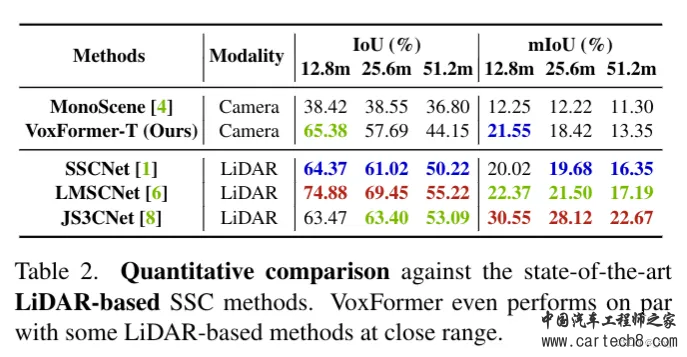 语义场景补全还是雷达比较强。主要特斯拉走纯视觉路线出的占用网格,大家也都跟着做视觉。国内感觉目前主流的贵的方案里面还是有用激光雷达,华为,理想,小鹏,小米等等。其实我知道的也不多,小公司信息比较闭塞。 7. OccupancyDETR: Making Semantic Scene Completion as Straightforward as Object Detectionhttps://arxiv.org/pdf/2309.08504.pdf arxiv.org/pdf/2309.08504.pdf
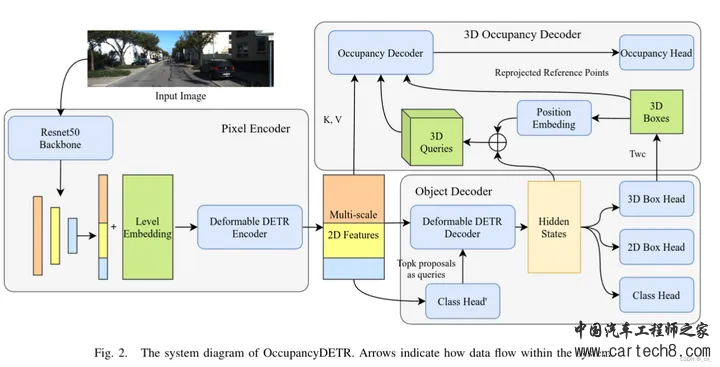 8.FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
9.COTR: Compact Occupancy TRansformer for Vision-based 3D Occupancy Predictionhttps://arxiv.org/pdf/2312.01919.pdf arxiv.org/pdf/2312.01919.pdf
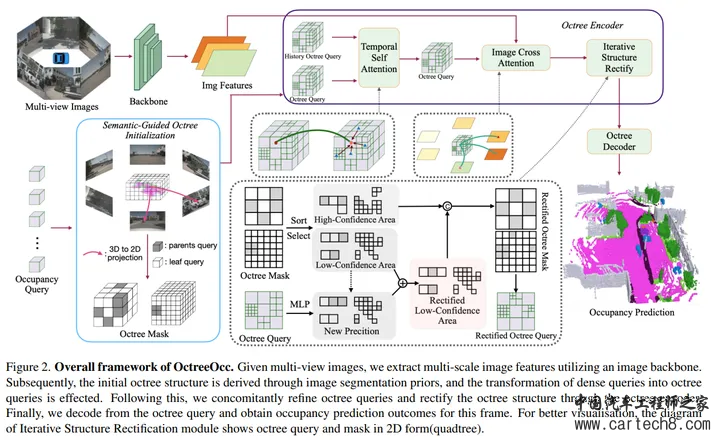
10. OctreeOcc: Efficient and Multi-Granularity Occupancy Prediction Using Octree Querieshttps://arxiv.org/pdf/2312.03774.pdf arxiv.org/pdf/2312.03774.pdf
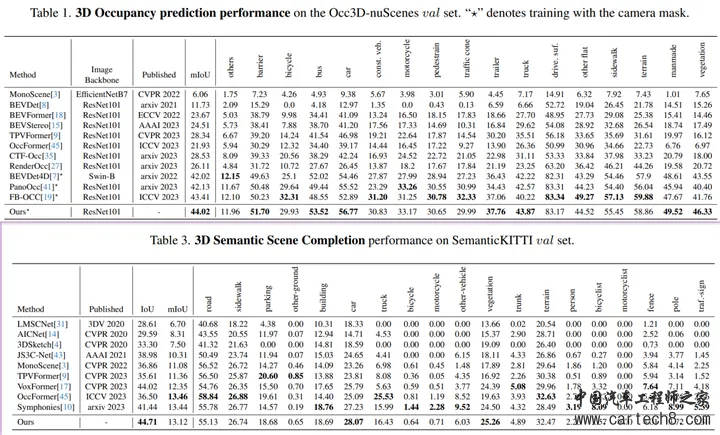  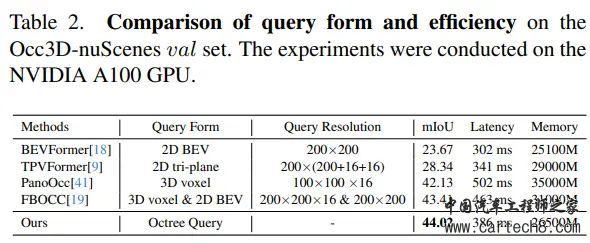 11. Fully Sparse 3D Panoptic Occupancy Predictionhttps://arxiv.org/pdf/2312.17118.pdf arxiv.org/pdf/2312.17118.pdf
Stereo-based抱歉这里把双目的语义补全单独列了出来,主要是单目可以当多目来用也还好,但双目输入来做占用网络就有些特别了,他要求是左右两个视图。而且上面也有说语义场景补全和占用网格的区别,所以可以简单看一下。 1. OccDepth: A Depth-Aware Method for 3D Semantic Scene Completionhttps://arxiv.org/pdf/2302.13540.pdf arxiv.org/pdf/2302.13540.pdf
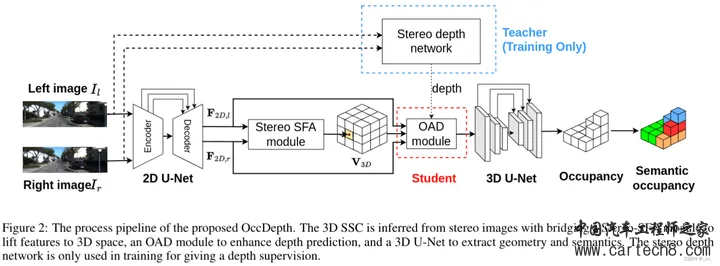 输入左右两个视图的图像过2D U-Net编码成二维特征F2D,l, F2D,r∈RH×W ×C。然后将二维特征融合到三维体素中,通过立体软特征分配(stereo - sfa)模块学隐式深度信息。接下来,通过占用感知深度(OAD)模块将显式深度信息添加到3D特征中。
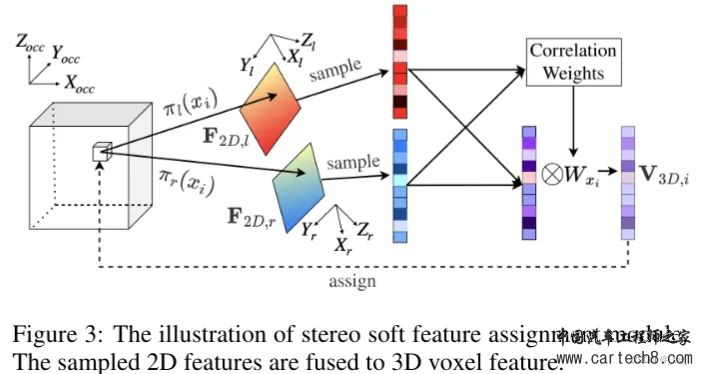 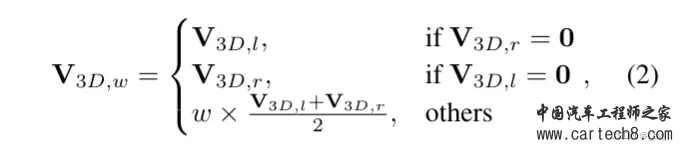 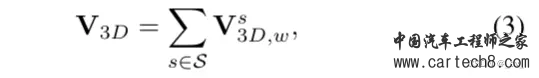 上面有三个方程,这三个方程就是Stereo Soft Feature Assignment Module的过程了。首先公式一中x是voxel的中心坐标,3D-2D投影表示为π(x),φx(M)是采样在坐标x处的特征映射M。直白的解释就是从图像特征中采样出对应的3D体素特征。当投影的2D点在图像之外时,3D特征将设置为0。 公式二是用来将从左右特征图中采样出的3D特征进行加权融合。其中 w 表示由 V3D,l 和 V3D,r 之间的相关性计算的权重。在文中用的是余弦相似度来衡量特征的相关性。可以和上面的图对应上。 公式三是为了扩大感受野,用的多尺度 2D 特征图,其中 S = {1, 2, 4, 8} 是一组下采样尺度。
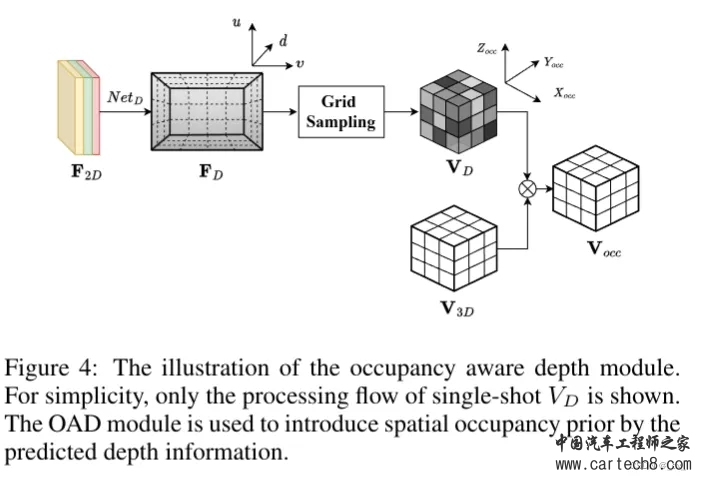 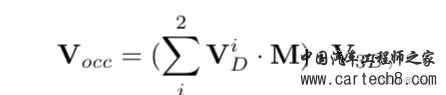 首先,单尺度图像特征F2d过来后,用一个NetD来预测多视图输入图像的深度特征 FD;然后使用 softmax 将FD变换为截锥体的深度分布GD,在然后利用摄像机标定矩阵P∈R3×4,将截锥深度分布GD转换为具有可微grid sampling过程的体素空间深度分布表达VD∈RX×Y ×Z。 公式中中 M 是用来平均左右两个输入之间重叠区域的体素像素的掩码,重叠区域的值为 0.5,其他值为 1.0,VD 可以表示为体素空间中的占用概率先验。然后乘起来拿到感知占用的体素特征Vocc。 2. StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completionhttps://arxiv.org/pdf/2303.13959.pdf arxiv.org/pdf/2303.13959.pdf
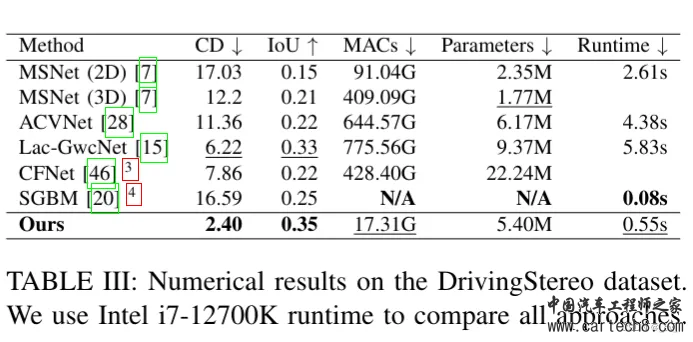
 在这篇paper对比的方法里提到了很多3D semantic scene completion的方法,有一些可能讲过有些没有,因为我们也不可能把所有的paper都看完,所以可以挑自己感兴趣的去看,一般文章里面都会有方法有做归纳总结,是基于什么什么的之类。 3. StereoVoxelNet: Real-Time Obstacle Detection Based on Occupancy Voxels from a Stereo Camera Using Deep Neural Networkshttps://arxiv.org/pdf/2209.08459.pdf arxiv.org/pdf/2209.08459.pdf
 小车车长下面这样  这个东西大家看效果就知道,只有占用没有语义  CVPR 2023 3D Occupancy Prediction Challenge这一类也比较特殊,属于没开源但实打实可以涨点的,可以学习一下技巧。 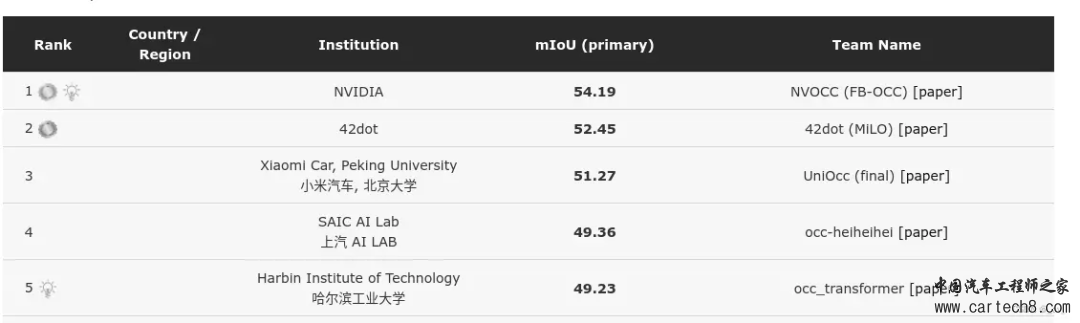 1. Scene as Occupancyhttps://arxiv.org/pdf/2306.02851.pdf arxiv.org/pdf/2306.02851.pdf
ok,benchmark就不说了,主要来看一下这个OccNet。 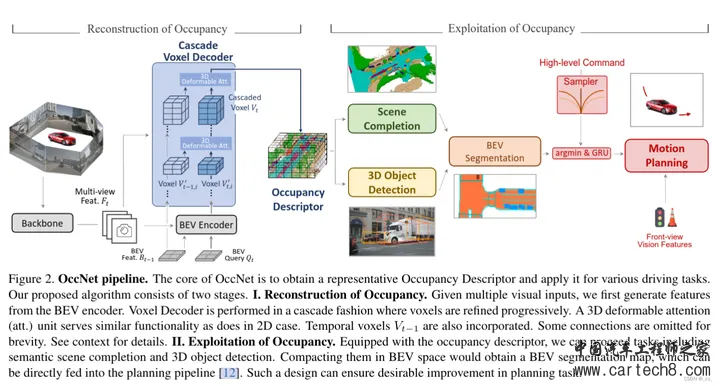 对于figure也是有原文解释的,大概的流程大家也能看出来,一个重建一个用途,篇幅有限所以只说重点Cascade Voxel Decoder。这个decoder是一个一个级联结构,用来逐步恢复体素特征中的高度信息。 从bev特征中重建出voxel是比较关键的,直接使用BEV特征或从透视图直接重构体素特征,会出现性能下降或效率下降,这一点在论文中给出了实验证明。所以将BEV特征(Bt∈RH×W ×CBEV)重构分解为N步,称为级联结构。这里 H 和 W 是 BEV 空间的 2D 空间形状,C 是特征维度,Z 是体素空间的期望高度。在输入的BEV特征和期望的级联体素特征之间,将不同高度的中间体素特征表示为 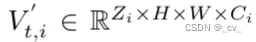 其中Zi和Ci分别在{1,N}和{CBEV,CVoxel}之间均匀分布。Bt?1和Bt两个时序上的bev特征通过前馈网络提升到V ' t?1,i和V ' t,i,经过第i个体素解码器,得到细化的V ' t,i,后面的步骤遵循相同的方案。每个体素解码器包括基于体素的时间自注意力(Voxel based Temporal Self-Attention)和基于体素的空间交叉注意力模块(Voxel-based Spatial Cross-Attention),并分别使用历史 V 't?1,i 和图像特征 Ft 细化 V 't,i。模型逐渐增加Zi,减少Ci,有效高效地学习最终的占用描述符Vt。就是说Z的高度是从C特征维度这里来的。而这里的时间自注意力和空间交叉注意力也见过是从前面bevformer那里来的,代码部分也是有继承bevformer。这里只是简单说一下,想要真的弄懂还是得一步一步去看代码。这里先简单说,后面如果我还有时间的话再写代码部分。 这里有个点,就是voxel的Z的高度从bev的C特征维度这里来的。基于这个做法在11月份的时候也有出一篇文章叫FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin,讲的就是这个故事,截止到2023年12月31日还没看到有中稿。大家知道有这种玩法就行了。 https://arxiv.org/pdf/2311.12058.pdf arxiv.org/pdf/2311.12058.pdf  2. Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Drivinghttps://arxiv.org/pdf/2304.14365.pdf arxiv.org/pdf/2304.14365.pdf
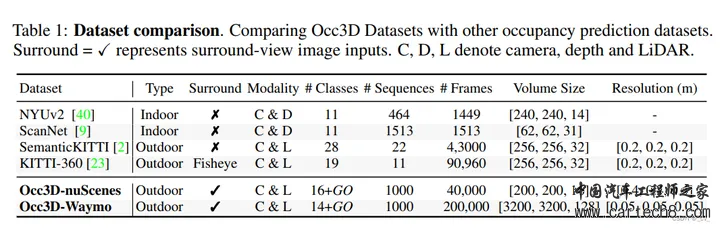 对比如下: 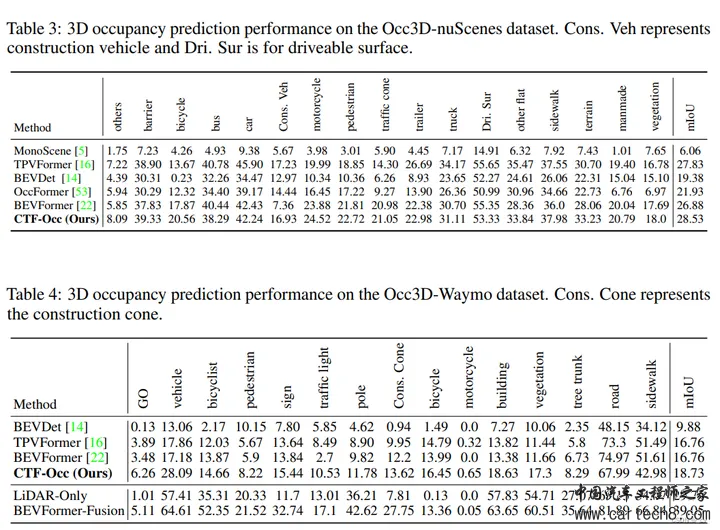 3. FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation[paper] opendrivelab.com/e2ead/AD23Challenge/Track_3_NVOCC.pdf
https://github.com/NVlabs/FB-BEV github.com/NVlabs/FB-BEV 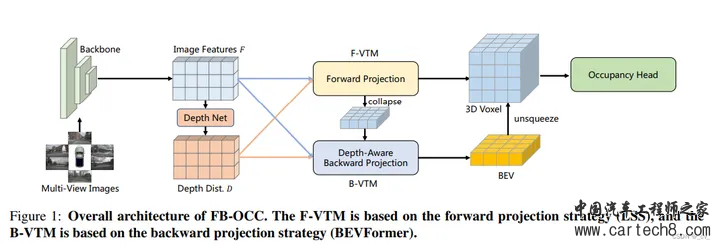
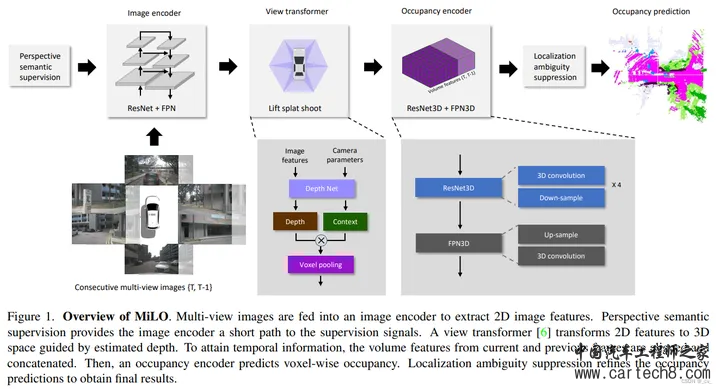
“ 4. MiLO: Multi-task Learning with Localization Ambiguity Suppression for Occupancy Prediction[paper] opendrivelab.com/e2ead/AD23Challenge/Track_3_42dot.pdf
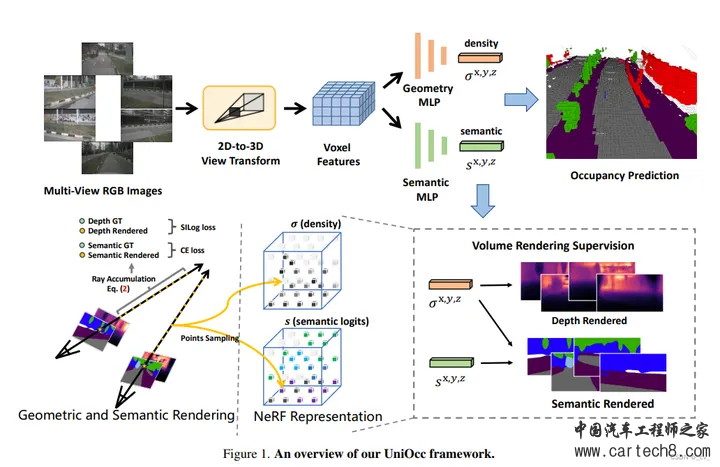
 5.UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering[paper] arxiv.org/pdf/2306.09117.pdf
 6. Multi-Scale Occ: 4th Place Solution for CVPR 2023 3D Occupancy Prediction Challenge[paper] opendrivelab.com/e2ead/AD23Challenge/Track_3_occ-heiheihei.pdf
我们的方法的总体架构如图1所示。给定具有T个时间戳的N个相机图像,我们首先使用2D图像编码器提取M个尺度特征。然后将图像特征提升为3D体素特征,然后在每个尺度上独立地对过去帧进行长期时间特征聚合,以构建当前帧的多尺度3D表示。为了彻底融合多尺度3D特征,我们使用轻量级的3D UNet来集成局部和全局几何和语义信息。我们使用2个解耦的头在最大分辨率上分别执行占用和语义预测。在训练过程中使用多尺度监督来促进收敛。最后,应用模型集成、测试时间扩充和类阈值来进一步提高性能。 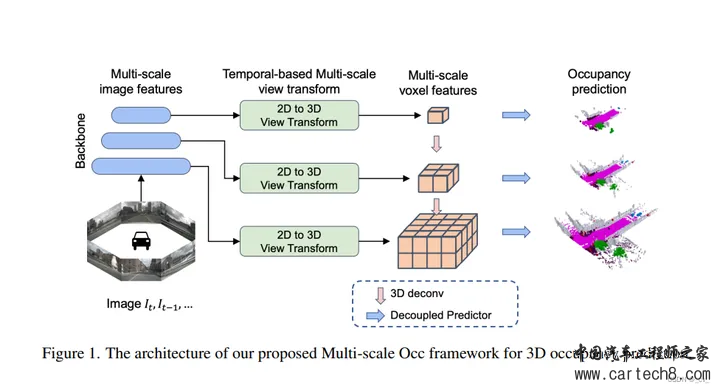 7. OccTransformer: Improving BEVFormer for 3D camera-only occupancy predictionhttps://opendrivelab.com/e2ead/AD23Challenge/Track_3_occ_transformer.pdf opendrivelab.com/e2ead/AD23Challenge/Track_3_occ_transformer.pdf
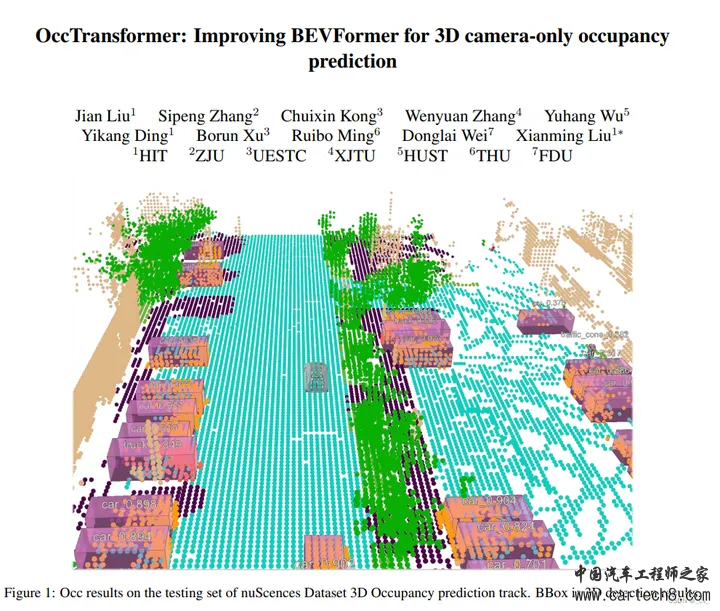 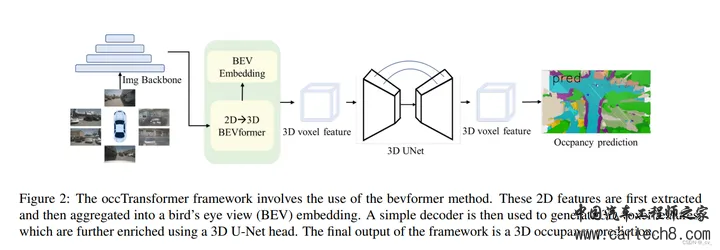 结语2023年12月31日,2023年最后一天了,在公司写完了这篇blog,这一年不能说是碌碌无为吧,也可以说是一事无成,2024希望自己越来越好,也希望自动驾驶越来越好!!! |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论