World Model猜想:将开启自动驾驶GPT时代
World Model猜想:将开启自动驾驶GPT时代
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
 CVPR 2023 自动驾驶workshop上Tesla和Wayve都提到了他们在利用生成大模型方面的最新探索方向,即大模型来生成自动驾驶相关的连续视频场景,Wayve将其命名为GAIA-1,并于前段时间发布,而Tesla则将自己的尝试命名为World Model。显然大语言模型基于生成模型取得了巨大的成功引爆了AI行业,而计算机视觉领域则只能翘首期盼取得类似的突破的时刻的到来。作为计算机视觉皇冠的自动驾驶行业,站在行业技术最前沿的科技公司给出了他们针对这个问题的答案,那就是生成式World Model。  Wayve官网上给出了GAIA-1的介绍和基于GAIA-1生成的素材 World Model是自动驾驶行业的Foundation Model 现在大家应该都清楚GPT是大语言模型中能力最强,最具影响力的Foundation Model,可以翻译成基石模型,能够被视作基石模型的大语言模型都有着巨大的参数量和庞大的训练数据集以及十分高昂的训练代价,其他一些Foundation LLM的例子还包括Anthropic的Cloude以及UC Berkeley开源的Vicuna等。业界普遍认为基石模型由于其工程复杂,研发成本高昂,未来也只会收敛到少量性能最佳的大语言模型,类似主流的智能手机底层操作系统只有iOS和Android,绝大多数应用则围绕这些基石模型进行开发。 大语言模型庞大的基石模型展现了超乎想象的智能表现和同样难以置信的巨大规模,之所以这样巨大规模的模型能够训练,离不开NLP领域发现了利用生成模型词语接龙或词语填空这样一个简单有效的自监督训练方法,利用这样的方法以及互联网上数千年来人类积累的海量文本数据,就可以训练出参数规模达到百亿千亿级别的性能卓越的巨大语言模型。然而计算机视觉领域一直以来非常依赖有标注的数据和监督学习,因此模型的规模受到价格高昂的标注数据的限制,整体反战是落后于NLP领域的。 但是实际上单纯依靠文本学习,可能LLM永远都无法达到接近人类的智力水平。我们想象一下,人类历史上从来没有哪个个体能够像GPT一样阅读并学习人类历史全部的文字信息,然而人类却有着目前最强的LLM模型也无法企及的分析,推理,演绎,并找到创新答案的能力。究其原因是人类从大脑还未完全发育的婴儿时期开始就在不停的观察环境,与环境互动,并在这个过程中获得大量语言所不能表达的信息和知识。因此单纯阅读文本信息从信息来源角度就无法跟人类大脑相提并郏?材压諳penAI希望能在GPT-5大力拓展多模态的能力,其实就是为了从单一文本信息源向信息更丰富的其他数据源进行拓展。  人类婴儿时期尚不具备语言能力就开始与世界不停的互动以训练自己的大脑掌握世间变化的基本规律 与NLP领域相比,计算机视觉技术处理的图像拥有更加丰富的信息,俗话说一张图顶得上千言万语,但是计算机视觉领域一直缺乏文字接龙这样简单而又蕴含丰富信息的自监督任务,究其原因文字本身便是人类进化过程中专门发明的传递信息的载体,因此文字的信息量虽然不及图片,但是信息密度非常的大,提取也非常简单。但是图片虽然信息蕴含丰富,可是信息密度比文字低,提取也十分困难。CNN成熟之前,人们甚至无法找到有效的方法提取简单的数字图片中蕴含的信息,而一张数字图片存储尺寸可能是其包含的数字信息的文本存储尺寸的几万倍。  CNN发明前人类甚至没有足够有效的技术手段提取数字图片中的信息 然而随着Midjourney和Stable Diffusion等图像生成模型取得了令人瞩目的进展,计算机视觉领域在如何构建类似文字接龙游戏这样不需要依赖标注信息的高效自监督任务上逐渐达成一定的共识,那就是通过生成模型来输入已知环境情况同时预测未来场景很可能就是构建计算机视觉领域自监督Foundation Model的关键性任务。 CVPR 2023 Tesla和Wayve展示的所谓World Model正是这种理念的产物。凭借自动驾驶车辆采集的大量实景视频数据,可以利用生成模型去生成未来场景来和真实的未来时刻数据对比,从而构建loss,这样就可以不依赖标注信息对模型进行训练。这个任务非常接近文字接龙,而它最巧妙的地方则在于要想成功预测未来时刻的场景,你必须对现在时刻场景的语义信息以及世界演化的规律有着深刻的了解。 试想一下,在前方出现事故这样一个场景里,预测整个交通环境的变化需要首先识别出事故场景,还要识别出其他交通参与者,并且知道这些交通参与者面对事故的一般反应,例如大多数车辆会选择绕行,工程救援车会停下来实施救援,如果现场有伤员可能还会有救护车到达,并且医生会对伤员进行救治,甚至自车的行为也会对周围其他参与者行为产生影响等等等等,通过尽量准确的预测未来可能发生的合理场景,模型就必须学会所有以上提到的复杂信息。而实际上人类正是因为从出生以来就一直不间断的处理这样的实际场景才能有着这样的对未来世界发展的合理推演能力,而这样的能力其实是智能的基石,因此通过要求模型不断预测下一步发生的情况的图像,并与实际发生的情况做比较,很可能能够推动自动驾驶智能,甚至是通用人工智能发生巨大的飞跃。  一起交通事故的图片,要预测下一时刻的发展需要读懂这张图片上蕴含的非常丰富的信息并掌握一定的常识 Tesla World Model与Wayve GAIA-1的实际效果 Wayve在 CVPR 2023之前就展示了不少GAIA-1的前瞻内容,GAIA的效果如下边视频,可以看到GAIA可以生成一些非常丰富的自动驾驶场景,包括大量行人,机动车以及非常具有英国特色的道路。在CVPR的分享中CEO Alex Kendall还举例说明了GAIA可以根据文字Prompt生成一些实际没有发生的场景,例如可以在一段视频通过prompt生成这辆直行或左转等多种不同的推演视频,甚至还能生成一些非常规的场景,例如车子偏离路面开到草地上等等。  video: https://mp.weixin.qq.com/mp/readtemplate?t=pages/video_player_tmpl&action=mpvideo&auto=0&vid=wxv_3245511100184510470 但是仔细观看会发现,GAIA-1生成的场景虽然很丰富,但是还是偏模糊,另外仔细观察连续帧会发现有些车子或背景会在推演过程发生形状颜色类型的跳边,这可能表明了现阶段GAIA模型还没有很好的理解事物变化的连续性。 CVPR 2023上Ashok展示了Tesla的World Model,与GAIA-1一样,Tesla World Model同样可以通过Prompt来生成一些具有变化的场景。但我们可以观察到Tesla World Model与GAIA的一些区别:首先World Model生成的素材非常接近FSD实车采集的视频,可以看到生成图片与Tesla实车差不多,都是Tesla特有的带滤镜的黄色调图像,这说明了Tesla World Model具备一定的传感器仿真能力,能够模拟一些传感器特性甚至是传感器缺陷。而且与GAIA不同,Tesla生成的是多视角的视频,Ashok还特意提到生成的视频中车辆在跨视角的时候位置,速度,形状能保持相对稳定,这说明了生成模型一定程度上的理解了相机间的几何布局以及物体经过的变化规律。  video: https://mp.weixin.qq.com/mp/readtemplate?t=pages/video_player_tmpl&action=mpvideo&auto=0&vid=wxv_3245512019945046017 另外Tesla World Model不仅能够生成RGB空间图像,还能够生成类似标注的语义信息,而这既表明了这项技术未来被利用在标注数据生成的潜力,也说明了模型具备了一定的对于语义的理解推演能力。  Tesla World Model具备一定的语义推演能力 自动驾驶World Model未来应用的一种可能性 显而易见生成式的World Model可以被用来当作一种仿真工具来生成仿真数据,特别是极为少见的Corner Case的数据。然而World Model更有潜力的应用方向我认为是World Model可能会成为像GPT一样的自动驾驶领域的基础模型,而其他自动驾驶具体任务都会围绕这个基础模型进行研发构建。 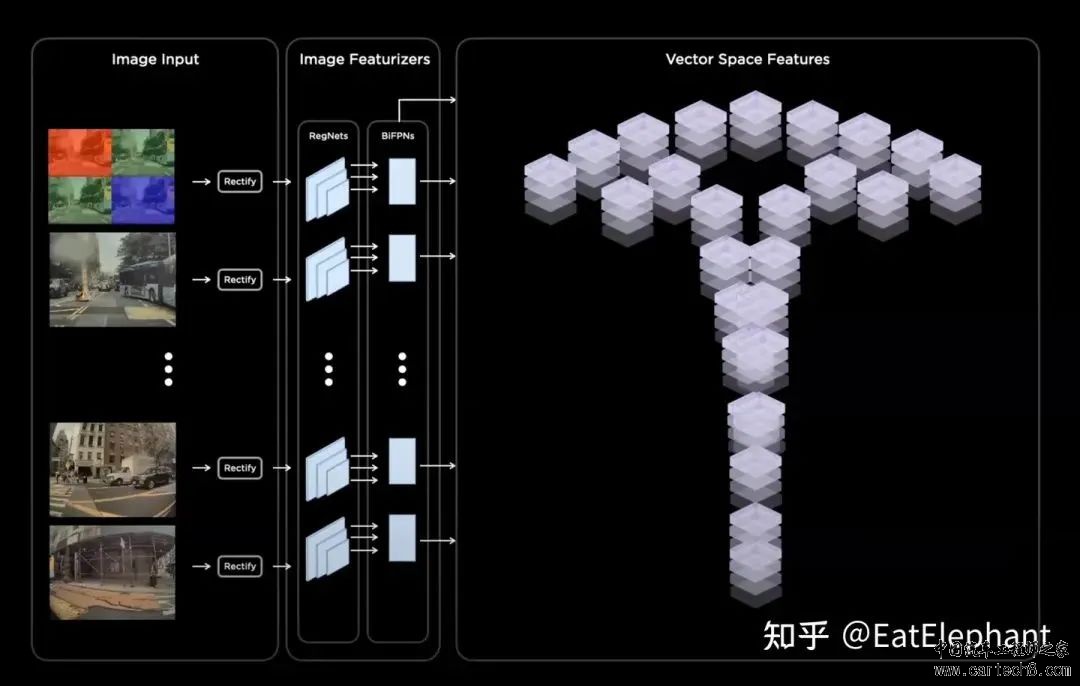 Phil Duan分享了这样一个比较粗糙的Foundation Model作为特征提取的应用概念 CVPR2023 Tesla的另一位分享者华人工程师Phil Duan分享了上面一张他理解的Foundation Model应用的图,图中那个由众多特征层组成的Tesla商标就示庾臚oundation Model提取出来的丰富特征,这张图可以看到非常粗糙,但是他想说明的实际上是通过Foundation Model可以提取非常丰富的语义信息,而随后所有的应用无论是动静态物体检测,Occupancy,Distance Field,围绕着这样一个功能强大的Foundation Model提取出来的丰富语义特征都能获得非常显著的性能提升,正如GPT的出现不是解决了一个NLP问题,而是在所有的问题上提供了一个通用的解决手段。 诚然,Tesla的World Model的研发应该还处于非常非常初期,即使是开发完善程度可能还略高的Wayve的GAIA-1,两者也都应该还处于实验室探索阶段。然而我们可以根据GPT的应用做一个猜想。GPT利用自监督的方式通过海量数据得到一个能力非常强大的模型,这个训练好的模型直接在推理阶段被用来执行后续的任务。那么自动驾驶Foundation Model使用的是图像生成技术,而现在最成功的图像生成技术无疑是Diffusion Model。如果Tesla或Wayve能够训练成功一个非常强大的Foundation Model,我猜测这个model也大概率是基于Diffusion Model的,而为了利用这个Foundation Model的强大能力,必然车端也要部署运行同样的基于Diffusion Model的模型。 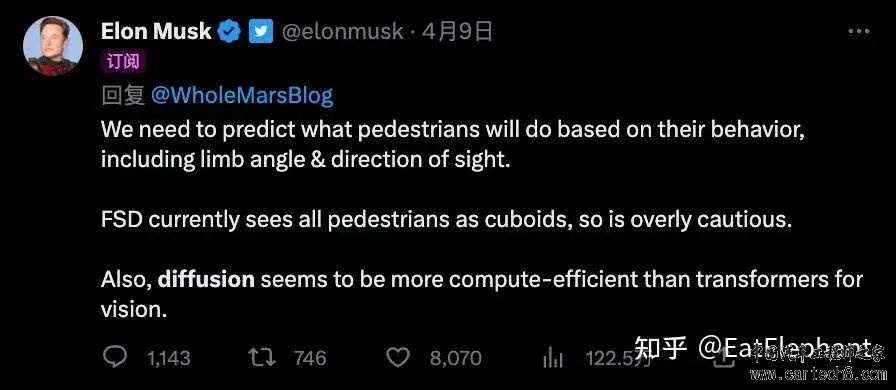 lon在twitter上两次提到diffusion model可能比transformer更加高效 恰巧的是最近Elon Musk在Twitter上两次提到Tesla正在研究Diffusion Model,而且他们发现Diffusion可能比Attention更加高效。这次CVPR 2023 Phil Duan明确说明Tesla不仅在图像转BEV的时候使用了Transformer,还在很多其他模块中也大量使用Transformer,而这次CVPR上Tesla和小鹏的Patrick都提到Transformer的部署优化至关重要,Tesla在实验Diffusion Model的性能效率,这说明Tesla很可能在努力尝试将FSD模型中大量使用的基于Transformer的特征提取层部分甚至全部用Diffusion Model的模型进行替代。 OK,通过上述分析,某个未来的模样似乎渐渐清晰,通过自监督方法训练Diffusion大模型获取Foundation Model,再基于这个Foundation Model来比现在好得多的效果进行自动驾驶的端到端任务执行,也许那就是自动驾驶自己的GPT时代来临的奇点吧! |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论