算力芯片,终局之战?
编者按写今天这篇文章的时候,我内心是焦虑的,甚至有点悲观。中国的芯片界同仁,不可谓不努力:充满艰难险阻的工作,数十年如一日的煎熬,直面国际巨头的竞争。
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
| 中国的芯片界同仁,不可谓不努力:充满艰难险阻的工作,数十年如一日的煎熬,直面国际巨头的竞争。在芯片具体产品层面,别人有性能优势,我们有价格优势。不敢说能打个你来我往,但至少还有还手之力。 然而,在计算生态方面,我们则完全没有招架之力。计算生态就像一只无形的手,抹去了我们仅有的一点可能的机会,阻挡着我们前进的步伐,让我们距离世界先进越来越远。 更令人焦虑的是未来:一方面,计算生态的作用在不断地加强;另一方面,不同领域不同处理器的计算生态有进一步融合的趋势,逐渐形成新的超级生态。两相叠加,一旦超级生态逐步建立,后进者再无翻身的可能。 未来5-10年,大算力芯片,将迎来终局之战。 1 计算架构的发展趋势1.1 计算架构的发展阶段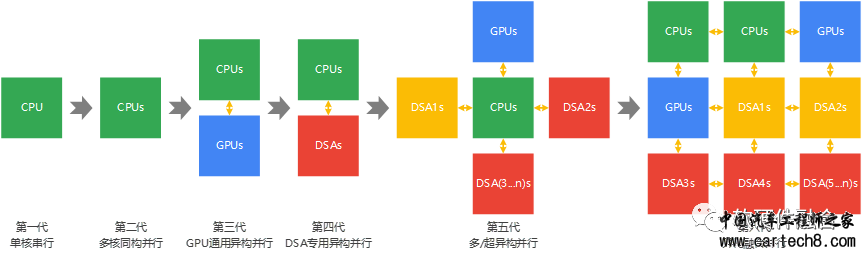 随着算力需求越来越高,同构CPU的业务场景越来越少,基于GPU或AI等DSA处理器的异构计算已经成为主流。从发展的角度看,随着大模型等算力场景的持续挑战,未来会进一步从异构计算走向异构融合计算。 如果按照处理器类型的数量进行分类,可以分为三个阶段:
行业在创新处理器的设计和实现方面进行了很多探索,比如存算一体、重构计算、类脑计算、量子计算等等。这些新型的计算架构设计或实现方法,从系统指令复杂度的视角,可以归属到DSA或ASIC的范畴。因此,这些创新,没有跳脱异构融合计算的大框架。 以我目前浅薄的认识,个人觉得:异构融合计算,将是计算架构的终极形态。 1.2 CPU同构,单个处理器,单个生态虽然仅仅只有一个处理器,但其计算生态已经是地狱级难度。 Intel x86架构的优势,是在众多处理器架构的厮杀中逐步确立的。随着x86的优势地位确立,基于x86架构的软件生态逐渐成熟,即便是Intel自己,也无法改变这一局面。  Intel的64位安腾(Itanium)处理器,是一个非常典型的失败的案例。安腾是Intel于2001年推出的64位架构的CPU处理器,Intel对之寄予厚望。虽然是Intel的亲儿子,虽然是功能强大的64位CPU架构,虽然安腾的架构和微架构设计非常优秀,但因为和x86的不兼容,完全一个新的生态,不可避免的走向了失败(2021年7月29日是安腾处理器最后的出货日期,英特尔正式告别了这款使用IA-64指令集的纯64位处理器)。 与此形成鲜明对比的,是AMD64的成功。2003年,AMD推出了业界首款 64 位处理器 Athlon 64,带来了AMD64(x86-64)指令集,即x86指令集的64位扩展超集,具备向下兼容的特点。因为向下兼容,继承性地往前发展,最终成就了AMD64的成功。 1.3 GPU异构,两个处理器,两个生态融合相对于Intel的x86 CPU计算生态是百家争鸣的胜者,NVIDIA GPU的CUDA生态,则是数年孤独后的一鸣惊人。 在NVIDIA GPGPU之前,GPU真的就只是GPU,即专用于图形计算的加速卡。这一时期的GPU,符合DSA的定义规范,可以当作是专用于图像领域的G-DSA。直到NVIDIA GPGPU的出现。 2006年,NVIDIA发布GPGPU。NVIDIA发现,图像处理有很多并行处理的部件,于是决定将这些专用的处理完全改造成通用的高效能小CPU核,于是GPGPU诞生了。虽然此时,GPGPU已经足够通用,但其编程难度很高,于是NVIDIA又贴心地开发了CUDA计算框架。即便如此,早期的CUDA功能并不强大,开发仍然不够友好。很多开发者并不看好,认为CPU多核才是正确的发展道路。 直到2012年,Alexnet的问世,深度学习时代的来临,NVIDIA GPU+CUDA才成了热门的计算平台,助推着NVIDIA市值超越一众竞争对手,成为全球市值第一的芯片公司。再紧接着,2018年,AI大模型逐渐流行。进一步把这股浪潮推向高潮,NVIDIA GPU一时间“洛阳纸贵”,同时,NVIDIA的市值突破了万亿美金大关。 我们再来看CPU和GPU的融合。 2022年初,NVIDIA正式宣布,收购ARM失败。假如,NVIDIA收购ARM成功,这场大算力芯片的“战争”,基本上可以提前给出结果:NVIDIA获胜,其他家永无出头之日。好在这件事情没有成行,算力芯片“战争”的结果,仍存在变数,这场“战争”仍在继续。 之后,NVIDIA退而求其次,与ARM的深度合作,开发了Grace系列高性能CPU,以及CPU+GPU整合的Grace Hopper系列超级芯片。 2 计算生态的极端重要性在之前,我一直以为Transformer之所以能够脱颖而出的最大原因就是那篇论文的标题:“Attention is all you need”,优势来源于算法本身。最近一段时间,跟好几位AI领域的专家交流下来,他们的观点是:有很大一部分原因是因为,Transformer比较好的实现了并行处理,能够最大限度的利用GPU并行的算力,因此才能够实现更大参数规模的大模型,进而获得更好的智能体验。 这个案例可以得到这样一个结论:只有NVIDIA GPU+CUDA生态亲和的模型才能最终走出来;如果不是NVIDIA GPU+CUDA架构和生态友好的模型,哪怕实际效果再好,也受限于模型效率、参数规模和成本等方面的劣势,无法脱颖而出。 或者说,大模型发展,强依赖于NVIDIA的GPU+CUDA计算生态。 在我的个人观点里,一直以来,都是非常重视生态的难度和重要性的。但最近几年,随着认识的进一步加深,我的想法得到了进一步修正。计算生态很重要,但过去10年左右的发展,使得计算生态的重要性,比我们大家想象的要更加重要:
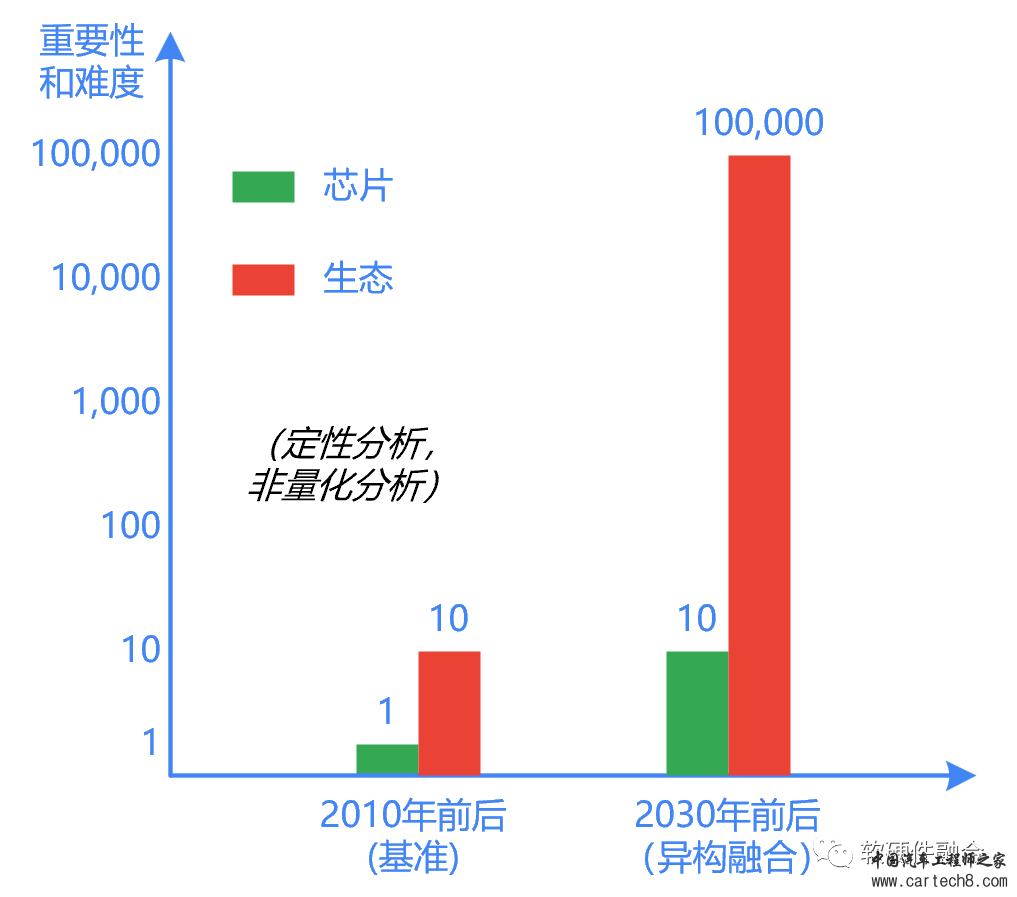 我们定性分析一下:
3 算力芯片,终局之战3.1 多异构融合,更多生态的融合 我们来分析一下Intel在多(超)异构和未来异构融合计算的布局:
Intel目前面临的挑战是:上面列出的很多内容,Intel提出之后,并没有非常有竞争力的产品去承载。 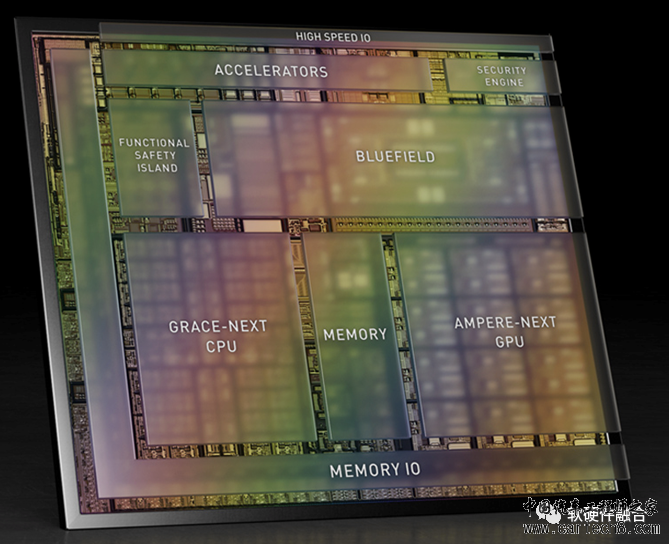 (注:图片为Altan结构框图,Thor和Altan一致) NVIDIA在汽车CCU方面,已经布局了Thor超级芯片,其核心计算部分由数据中心架构的Grace CPU、Ampere GPU、Bluefield DPU组成。一方面算力强劲,把汽车变成了一台超级计算机;另一方面,其架构跟数据中心处理器架构完全一致,为未来云边端融合提供了坚实的物理基础。 据说,NVIDIA在数据中心的CPU、GPU和DPU三芯片集成的、多种异构融合计算架构的超级芯片,已经在研发中。 3.2 异构融合,最后一场战役 (在电影《复仇者联盟》里,大反派灭霸一个响指,宇宙间众多生命,瞬间灰飞烟灭。) 在GPU领域,NVIDIA构建了牢不可破的CUDA计算生态;在DPU领域,NVIDIA拥有全球最好的DPU芯片,以及功能强大的DOCA计算框架;高性能网络可以看做DPU的一个重要的功能子集,NVIDIA拥有全球最好的高性能网络RDMA和独一无二的Infiniband技术,高性能网络是AI大模型训练集群的核心技术;在CPU领域,NVIDIA和ARM深度合作,抢占了比较有利的生态位。  一根筷子,轻轻地就会被折断;十双筷子,则牢牢地抱成一团,几乎牢不可破:
在未来5-10年,随着生态的极端重要性进一步凸显,大算力芯片,即将迎来“终局之战”。 4 唯一可能的破局之道:开放 (在电影《复仇者联盟》里,奇异博士给钢铁侠伸出了一根手指,意思是说,那一千四百多万分之一的成功可能性,就在此刻。) 回到现实,大算力芯片的计算生态之争,“唯一可能”的破局之道:开放。“唯一”是说,有且仅有这一个办法;“可能”指的是,这个方法虽然存在赢的几率,但几率很低很低。 4.1 异构融合计算,架构必须收敛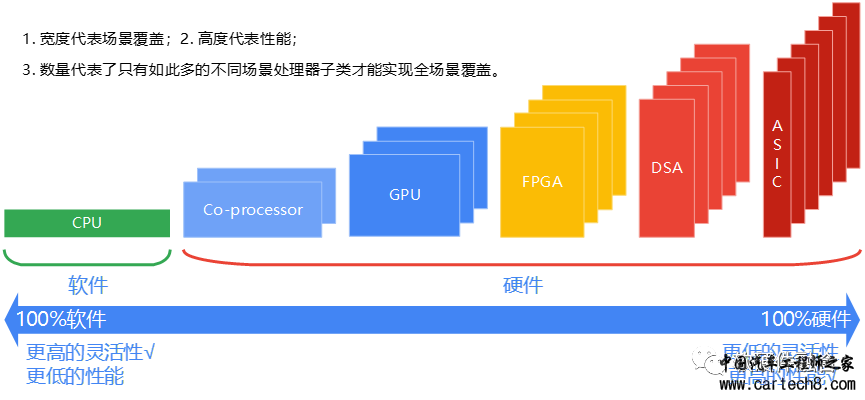 指令复杂度越高,单个处理器引擎覆盖的场景就会越小,全场景覆盖所需的引擎种类就会越多。从CPU到ASIC,处理器引擎越来越碎片化,构建生态越来越困难。 异构融合计算时代,集成的处理引擎类型和数量越来越多,处理引擎架构越来越多,芯片平台的数量也越来越多,所处的位置(云网边端)也越来越丰富。 解决办法只有一个:让架构收敛。每一个类型或子类型的处理器,全球全行业能够形成标准的架构和接口。 不确定的是,未来是走向封闭的一家通吃?还是行业形成共识,大家基于开放架构做产品,行业走向基于产品竞争力的、真正的“公平”竞争? 4.2 除了最强者,开放是其他家的唯一选择只要你不是第一,第二名能做的也只能是开放。 开放阵营,不仅仅会包括行业里的二线、三线芯片公司,以及广大的Startup公司,还会包括目前仍处于一线大厂的众多知名公司。 从目前看可见的未来,NVIDIA会是最后赢者通吃最有优势的那个。那么,这个阵营包括Intel、AMD、高通、博通、Marvell等知名芯片公司,也包括互联网巨头等芯片的大客户,如苹果、谷歌、微软、华为、阿里、腾讯等,也包括OpenAI等AI/AGI新贵。对抗巨头的唯一做法,唯有凝聚共识,开源开放。 4.3 开放,让大家回到同一起跑线我们设想一个乌托邦的时代,在这个时代里:
那么,这个时候,大家会回到同一个起跑线:靠产品能力说话,而不是依靠无形的手——生态的力量。 |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论