一种优化Freespace检测效能的智驾感知提升算法
作者 |泉歌出品 |焉知汽车知圈|进“AI大模型群”,加微13501975564,备注AI高级驾驶辅助系统(ADAS)开发中最关键的问题之一是汽车周围环境的描述方式。环境可以分为动态和静态部分。第一个用于描述所有可移动物体,如 ...
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
 作者 | 泉歌 出品 | 焉知汽车 知圈 | 进“AI大模型群”,加微13501975564,备注AI 高级驾驶辅助系统(ADAS)开发中最关键的问题之一是汽车周围环境的描述方式。环境可以分为动态和静态部分。第一个用于描述所有可移动物体,如汽车或汽车等。行人。第二个代表静态障碍物,如护栏、路缘石、建筑物或障碍物等。为了在拥挤的环境中自由移动,需要提供有关所有周围障碍物的高精度信息。有一个可用于此目的的广泛表示,即 2D和 3D 网格、区间图、原始结构和轮廓。 根据应用,不同表示形式具有不同程度的复杂性。此外,大多数表示都依赖于传感器。之所以如此,是因为用于创建特定表示的算法依赖于传感器的物理规格和限制,目前市场上可以找到使用雷达、摄像头或激光雷达等传感器的解决方案。然而,传感器依赖性是一个不允许进一步改进的问题,可以通过直接使用来自不同类型传感器的输入来获得。将来自各种传感器的信息组合成一个表示的一种可能方法是占用网格,这种方法可以解释为作为传感器融合。不幸的是,由于内存和处理能力有限,占用网格并不是嵌入式系统的最佳解决方案。此外,将网格作为一组单元格的原始表示形式,填充了简单的占用概率,并不是真正有用的用于后续的上层 ADAS 感知算法。由于数据量很大且接口带宽有限,因此无法通过 CAN 等常见汽车接口轻松发送。这可以通过在占用之间添加一层参数化自由空间Parametric Free Space,PFS(PFS 通过参数化方法描述已知没有障碍物的区域的边界曲线,这种对主车静止环境的紧凑描述可以有多种形式,这种描述的一种灵活而紧凑的形式称为参数自由空间)来消除这些复杂网格的对应数据位(如下图),这样可以提供周围环境的紧凑描述。 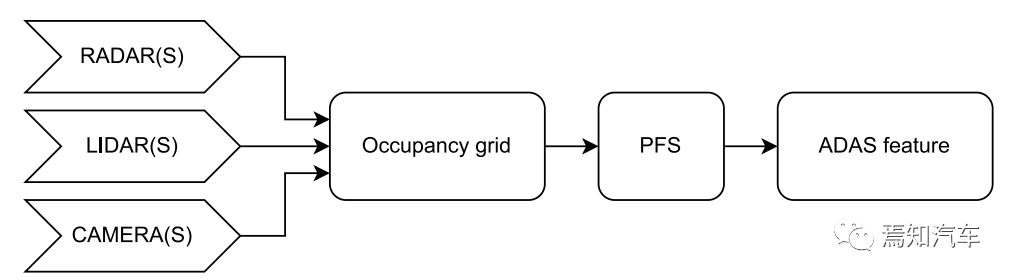 简而言之,PFS 确定包括两个主要步骤。PFS 的输入是占用网格,该算法从使用图像处理技术进行网格预置开始,结果是生成一组代表自由空间边界的网格单元。然后对这些单元进行近似最终结果的一组预定义数量的控制点,代表给定次数的样条曲线,这样可以很容易地被后续ADAS算法使用。 问题描述 在汽车行业中,所有感知算法都是循环执行的,并且必须在预定义长度的时隙(例如 50 ms)内处理当前输入,当前,有多种方法可以满足严格的实时要求。第一个想到的想法,就是使用更好的CPU单元。这样的解决方案并不令人满意,因为它会产生相当大的成本,从而降低产品的竞争力。基于摩尔定律上看,即使成本不会成为问题,有些算法根本无法达到时间限制,这意味着最合理的解决办法是算法优化。 本文不关注代码实现形式的优化问题,而是关注一般方法。讨论的参数化可行使空间检测 PFS 确定算法是从图像处理操作开始,将其输入占用网格转换为一个二进制文件,这些文件中仅限制目标周围自由区域的单元具有非零值,所有其他单元均为零。由于在自由区域中,代表该边界的像素数量不是固定的,它可以在周期和场景之间变化(如下图a)。这里假设设置可行驶区域的单元方式构成是由有序像素的组成方式来进行连接闭合边界。 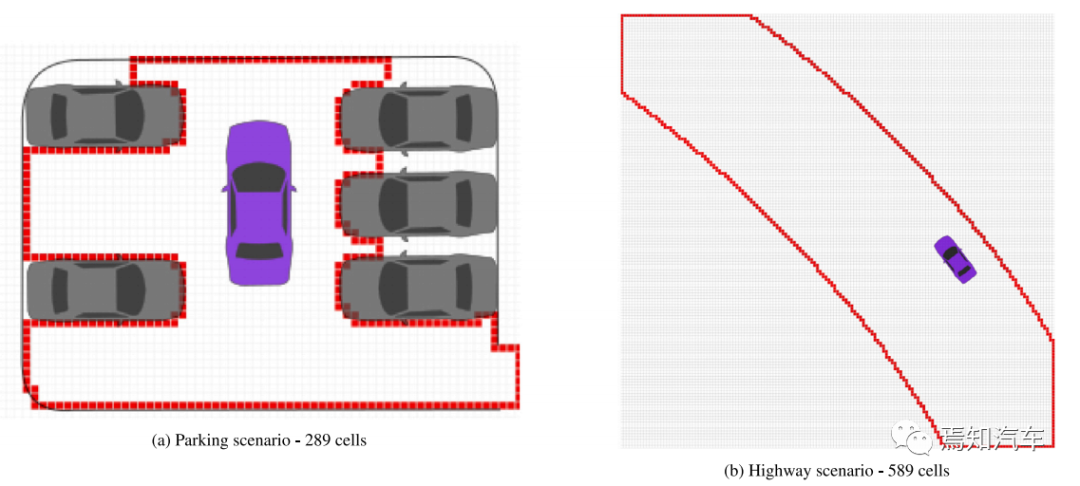 边界单元的动态数量 在处理的第二阶段,边界像素集是用参数样条曲线进行近似的。这种近似可能产生以下负担:不必要的高计算复杂度,因为通常大多数像素不提供附加信息的。而且,在每个计算周期,边界点的数量可能不同。如上图b表示不太拥挤的道路环境将有更多的自由空间,因此边界由更多的单元组成。 由于测量尺寸(边界像素的数量)没有严格定义的上限,因此需要在内存中保留足够多的空间来满足所有可能的情况。此外,边界像素的数量在每个周期之间可能会有所不同。这些方面在嵌入式系统中并不受欢迎(大多数嵌入式系统甚至不允许动态内存分配)。 一旦完成图像处理并确定边界像素,单元定义的边界将通过参数曲线(b 样条曲线)来近似。它由状态空间模型表示为: 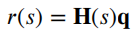 其中, 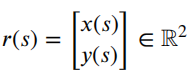 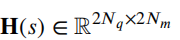 表示观测矩阵,其中的q表示为: 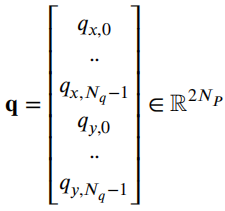 是作为一组2维B样条控制点的状态向量,Nq是控制点的数量,Nm是测量点的数量,qx,n表示第n个控制点的纵向位置,qy,n表示第n 个控制点的横向位置。 使用信息滤波器在每个周期递归地完成近似,这对于大量测量点而言比经典卡尔曼滤波器计算效率更高。即使进行了这种优化,大量测量仍然是一个问题(模型被视为单个 2D 测量,并用于更新两个样条函数x(s)和 y(s)。此外,为了能够使用信息过滤器,必须预先在每个循环进行计算观测矩阵H(s),其大小(行数)严格取决于测量次数。 针对一般点云的数据缩减,人们提出了许多方法。比如,通过基于所需点数缩减的比率搜索点子集来实现。 本文介绍的方法最小化了原始集和缩减子集之间的几何偏差。还有另一种方法由两个步骤组成。第一步,通过八叉树结构对点云进行正则化和压缩。第二步,点云根据曲率规则进行简化。这种方法与八叉树结构有一些相似之处。还有一些基于kmeans聚类算法的自适应简化方法。唯一的数据缩减(向下选择)在曲线拟合上下文中找到的算法是“正切函数”专用于非均匀有理B样条 (NURBS) 近似的方法”。 在该方法中,向下选择步骤包括三个连续原始测量点的局部二次插值,以查找沿定义的二次插值的斜率符号的变化空间轴。如果检测到斜率变化,则向下选择最近的测量点,然后将其做为 NURBS 的控制点。否则,不向下选择任何测量点。 解决方案 为了解决上一节中描述的大量测量的问题,这里提出了三种测量下选算法。 1、测量点分布均匀 PFS算法的一个假设是所有测量点均匀分布。这意味着样条曲线和测量点的起点和终点相对应。基于此,最简单(朴素)的下选算法是取每个第k测量点(mx,k,my,k),并根据以下公式: 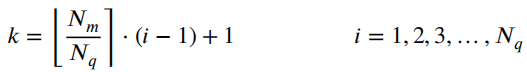 该解决方案的缺点是它强制样条线的每个控制点只有一个测量点,这可能不足以准确反映周围环境。 2、“Line”向下选择 本段和下一段中描述的算法集中于以下思想:仅保留行测量的特征点,并过滤掉所有冗余的点,即那些不提供有关边界形状的有价值信息的点。 “线”向下选择是通过使用线性方程y=ax+b来过滤特征点(即单元格表示形式),其想法是拒绝尽可能多的共线点。整个边界被分为相同长度的部分,部分端点是用虚拟线连接。 然后,对于该部分(其端点之间)内的每个点(像素),计算到该线的距离(例如下图中绿色特征点连接的红线部分)。如果该点的距离较大于阈值,该点被视为特征点。 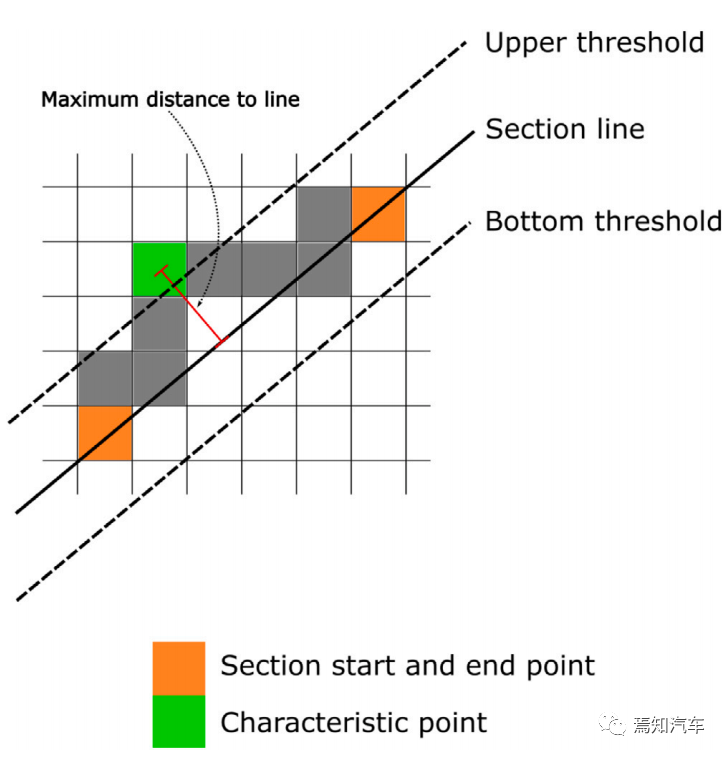 所有比该阈值更接近直线的像素都被认为是冗余的。一段的每个终点也是下一段的起点,也被视为特征点,保留这些点的好处是每个样条控制点(假设截面长度足够小)至少有一个支撑测量点。该算法通过寻找部分端点之间的特定点来扩展简单统一方法。 3、边界方向的下采样 为了限制额外操作的数量,寻找特征点,基于“方向”的方法仅限于对像素进行简单操作。其想法是检查从前一个像素到感兴趣像素的移动方向是否正确。并且从感兴趣的像素到下一个像素,按照该顺序,是相同的。如果不同,则中间点被视为特征点。例如,如果所考虑的点之前和之后的移动方向是往右上角(见下图所示)的,则该点不被标记为特征点。但如果连续移动方向不同,则该点被标记为特征点。 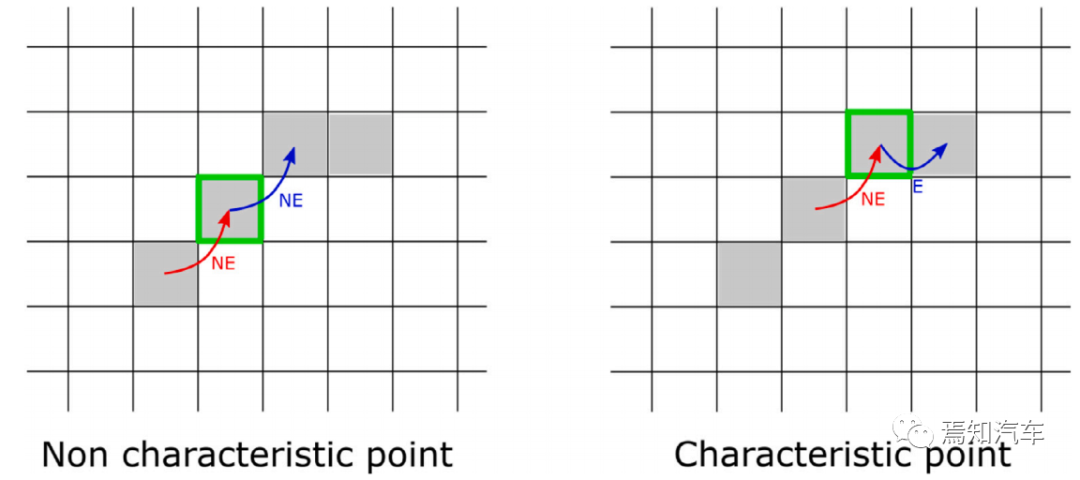 算法优势的不同维度对比 为了避免操作系统对计算时间估算的影响,需要重复测试多次并取平均值。最终的计算时间在下一节中给出,是所有场景中最长的时间。比较最长时间而不是平均值更有价值,因为无论汽车周围环境多么复杂,每种算法都应该在有限的时间内完成其工作。 1、降采样大小 如下图表示包含每种方法每个周期的平均测量点数量。正如预期的那样,与不使用降选方法相比,Original表示所提出的下采样方法中每个周期的平均测量点数量。本文提出的方法显着减少了测量点的数量,“Uniform”算法平均值减少了 16.74 倍,基于“Line”的算法平均值减少了 11.61,基于“Direction”方法则只有 2.15。  因此,大多数点都是使用“Uniform”方法过滤的。过滤的点数正好是使用的样条控制点的数量(即100)。“Line”方法作为前一种方法的扩展,添加了重要的点。这两种方法比前一种方法要好得多。“Direction”方法仅将测量点的数量减少大约 2 倍。其主要原因是该方法实际上表现得更像插值器,因此它不能很好地处理噪声数据,在这种情况下,噪声数据可能是一个复杂的边界形状。 2、计算时间 正如第一段所述,主要目标是减少计算时间,以满足算法执行的实时性要求,耗时比较如下表2所示。 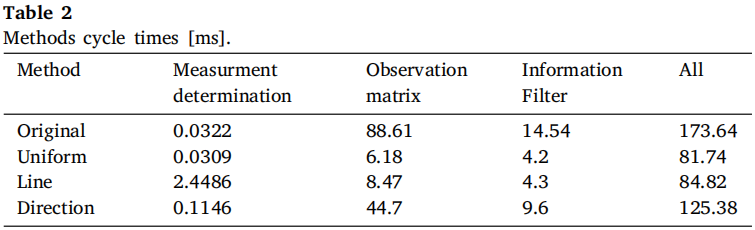 表2的每一行都显示了测试方法的结果,表中只列出了下选影响的PFS算法阶段,乍一看,所提出的解决方案比原始算法至少快1.38倍。在观测矩阵计算中尤其明显,更少的测量次数有助于将该阶段的运行时间提高 14 倍。 3、准确性/质量比较 由于PFS是主动安全系统的一部分,所以可以用分类器来评价,我们可以采用完整的(不是下选的)一组边界像素为参考,则每个逼近样条的点都可以落入以下事件之一: TP 真阳性 — 偏差(样条点与相应边界点之间的距离)低于定义的最大允许偏差。 FN 假阴性 — 样条点超出参考边界像素之外的最大允许偏差。 FP 误报 — 样条点超出最大允许偏差但在参考边界像素内。 根据上述事件,计算以下指标: TPR 真阳性率 — 衡量正确识别的实际阳性结果的百分比。 PPV:阳性预测值 — 定义测量的性能。 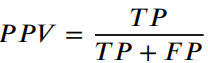 F1:F1 分数 — 是分类准确性(包括精确率和召回率)的综合衡量标准。 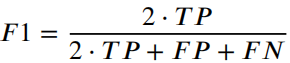 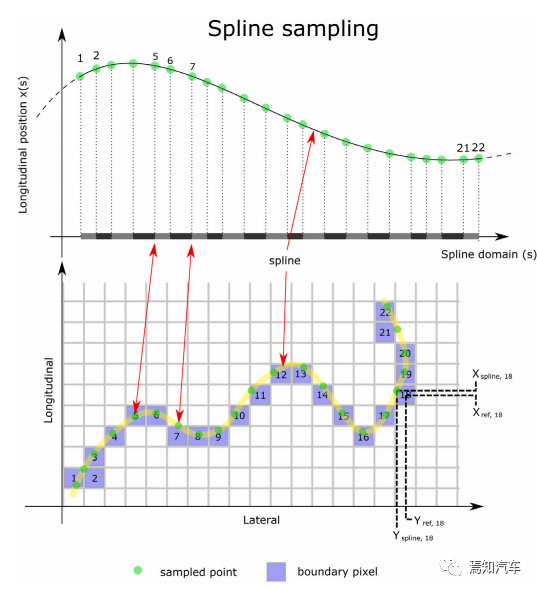 样条采样示例——纵向部分 使用上述指标的目的是从安全角度评估道路基础设施分类结果,显然,障碍物被错误分类为自由空间,比自由空间分类为障碍物更危险。 4、自由空间估计精度 使用一组 20 个不同的场景日志进行精度分析,并使用每种下采样算法重新模拟。由算法的图像处理部分生成的测量点集用作参考。这是一个足够多的选择,因为每个所提出的方法不会影响原始测量点集,而只会执行下选择。为进行比较而进行的整个统计分析依赖于这样的假设:生成的样条是在与边界像素向量具有相同分布的点处进行采样的。因此,如果边界由 321 个点组成,用于样条更新,则样条会在沿整个长度均匀分布的 321 个点中采样(如上图)。对于每个点,计算与参考的偏差进行最终汇总。如下图显示了所有算法的误差累积分布。 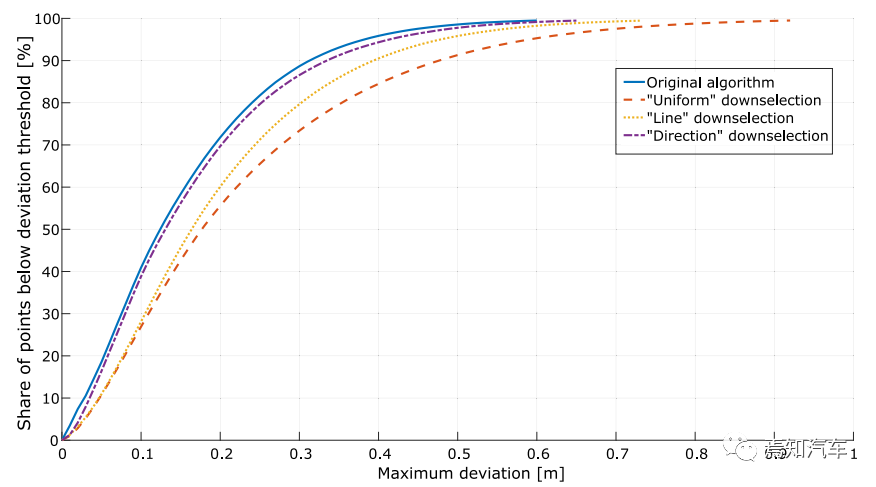 正如预期的那样,根据所使用的测量点的数量,基于“Direction”的算法获得了最好的结果,基于“Uniform”算法获得了最差的几何近似值。为了决定应该采取哪种解决方案,让我们考虑两个质量因子Qtime,它更关注计算时间Qmemory,它专注于内存计算。在这两种情况下,值越高表示结果越好。  Xref,k - 参考点的纵向位置(像素中心)yref,k - 参考点的横向位置(像素中心)Xspline,k - 样条线采样点的纵向位置对应于Xref,k,yspline,k- 样条线样本点的横向位置对应于yref,k。K - 点索引Mi- 第 i个周期的参考点(像素)数量(周期之间有所不同)N - 周期数(来自所有使用的日志)T - 每个周期的平均计算时间Nall - 所有测量点的数量 Nreduce - 减少的测量点数量 总结 参数曲线可以是智能汽车感知系统中自由空间边界的紧凑表示。在这样的应用中,它通常通过占用网格上自由空间和占用空间之间的边界的近似来获得。近似这种边界处理的现有算法具有大量必须处理的测量点(也即网格单元)。实际上,其中许多点是冗余的并且不添加任何信息。为了降低对处理能力的需求,一般可以拒绝对这些冗余点进行进一步处理,也不会降低近似的质量。本文介绍了几种可以达到这一目标的下采样算法,所有算法都使用通用的统计指标进行比较。算法性能的比较是在代表不同道路场景的数十条日志的基础上进行的。 实验表明并证明,对于使用所提出的方法的所有测试用例,PFS 计算中的运行时间和内存需求都可以显着降低,同时可以保持性能(准确性)。这对于资源有限的汽车嵌入式系统非常重要。所提出的下选算法在数据减少、执行时间、准确性和安全性方面进行了比较。总体而言,“线”算法是最有前途的一种。它提供了算法效率(即时间/内存消耗)和性能(准确性)之间的最佳平衡。对于未来的工作中,人们可以研究整个处理流程的其他步骤,特别是图像预处理步骤等方向,因为它仍然是最耗时的部分。  |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论