短小精悍的BEV实例预测框架:PowerBEV
短小精悍的BEV实例预测框架:PowerBEV
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
论文标题:PowerBEV: A Powerful Yet Lightweight Framework for Instance Predictionin Bird’s-Eye View 导读: BEV(鸟瞰图)发展至今,已然成为自动驾驶特征不可或缺的重要部分。然而,过于繁重的算法架构和输出冗余使得基于BEV的自动驾驶算法不能直接投入量产使用,本文提出了一个短小精悍的BEV实例预测框架,提高BEV算法部署和应用的效率。  准确感知实例并预测其未来运动是自动驾驶汽车的关键任务,可使其在复杂的城市交通中安全导航。虽然鸟瞰图(BEV)表示法在自动驾驶感知中很常见,但其在运动预测设置中的潜力却较少被发掘。现有的环绕摄像头 BEV 实例预测方法依赖于多任务自动回归设置和复杂的后处理,以时空一致的方式预测未来实例。在本文中,我们偏离了这一模式,提出了一种名为 "POWER BEV "的高效新型端到端框架。首先,POWER BEV 并非以自动回归的方式预测未来,而是使用由轻量级二维卷积网络构建的并行多尺度模块。其次,我们证明了分割和向心倒流足以进行预测,通过消除多余的输出模式简化了以往的多任务目标。在这种输出表示法的基础上,我们提出了一种简单的、基于流经的后处理方法,这种方法能产生更稳定的跨时间实例关联。通过这种轻量级但功能强大的设计,POWER BEV 在 NuScenes 数据集上的表现优于最先进的基准,为 BEV 实例预测提供了另一种范例。 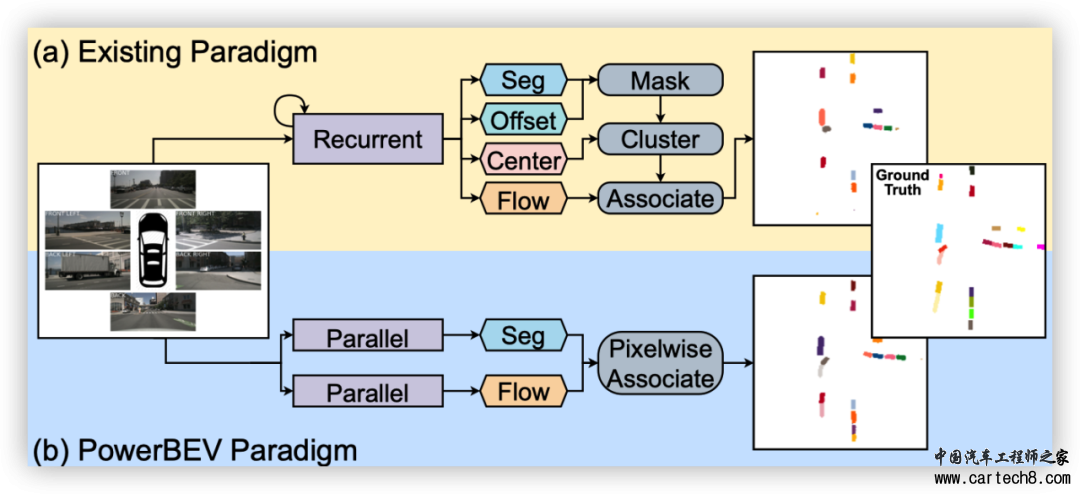 ▲图1|PowerBEV和其他模式的对比  准确获取周围车辆信息是自动驾驶系统面临的一项关键挑战。考虑到驾驶环境的高度复杂性和动态性,除了目前对道路使用者的精确检测和定位外,预测他们的未来运动也非常重要。一种广为接受的模式是将这些任务分解为不同的模块。在这种模式下,首先通过复杂的感知模型对感兴趣的物体进行检测和定位,并在多个帧中进行关联。然后,通过参数轨迹模型,利用这些检测到的物体过去的运动来预测其未来的潜在运动。但由于感知和运动模型是分开进行预测的,因此整个系统在第一阶段很容易出现误差。 近年来,许多研究都证明了鸟瞰图(BEV)表示法在以视觉为中心的精确驾驶环境感知方面的潜力。为解决误差累积问题,研究人员试图利用端到端框架直接确定 BEV 中的物体位置,并以占位网格图的形式预测全局场景变化。 如图1和图4所示,虽然采用了端到端范例,但现有方法预测了多个部分冗余的表征,如分割图、实例中心、前向流和指向实例中心的偏移。这些冗余表征不仅需要各种损失项,还需要复杂的后处理才能获得实例预测。 在这项工作中,我们简化了之前工作中使用的多任务设置,并提出了一种只需要两种输出模式的方法:分割图和流量。具体来说,我们直接从分割中计算实例中心,从而省去了多余的单独中心图。这也消除了估计中心和预测分割之间不一致的可能性。此外,与前人使用的前向流不同,我们计算的是向心后向流。这是一个矢量场,从当前每个被占据的像素点指向上一帧中其对应的实例中心。它将像素级关联和实例级关联合并为单一的像素实例分配任务。因此,不再需要偏移头。此外,这种设计选择还简化了关联过程,因为它不再需要多个步骤。与自动回归模型相比,我们还发现二维卷积网络足以让所提出的 POWER BEV 框架获得令人满意的实例预测,从而形成一个轻量级但功能强大的框架。 我们在NuScenes数据集上对我们的方法进行了评估,结果表明我们的方法优于现有框架,并达到了最先进的实例预测性能。我们还进一步进行了消融研究,以验证我们强大而轻巧的框架设计。 我们的主要贡献可总结如下: ●我们提出了 POWER BEV,这是一种新颖而优雅的基于视觉的端到端框架,它仅由二维卷积层组成,可对 BEV 中的多个物体进行感知和预测。 ●我们证明,冗余表征导致的过度监督会损害预测能力。相比之下,我们的方法通过简单的预测分割和向心后向流就能完成语义和实例级代理预测。 ●基于向心后向流的分配方案优于之前的前向流和传统的匈牙利匹配算法。  ■3.1 BEV针对基于相机的3D感知 虽然基于激光雷达的感知方法通常会将三维点云映射到 BEV 平面上,并进行 BEV 分割或三维边界框回归,但将单目相机图像转换为 BEV 表示仍然是一个难题。虽然有一些方法结合激光雷达和相机数据生成 BEV,但这些方法依赖于精确的多传感器校准和同步。 LSS(Lift Splat Shoot)可被视为第一个将二维特征提升到三维并将提升后的特征投射到 BEV 平面上的工作。它将深度离散化,并预测深度分布。然后,图像特征将根据该分布在深度维度上进行缩放和分布。BEVDet 将 LSS 适应于从 BEV 特征图进行 3D 物体检测。2021 年特斯拉人工智能日首先提出使用 Transformer 架构将多视角相机特征融合到 BEV 特征图中,其中密集 BEV 查询和透视图像特征之间的交叉关注充当视图变换。通过利用 BEVFormer和 BEVSegFormer中的相机校准和可变形注意力来降低变换器的二次方复杂性,这种方法得到了进一步改进。此外,已有研究表明,BEV 特征的时间建模可显著提高三维检测性能,但代价是高计算量和内存消耗。与检测或分割不同,预测任务自然需要对历史信息进行时间建模。为此,我们的方法在 LSS 的基础上使用轻量级全卷积网络提取时空信息,既有效又高效。 ■3.2 BEV未来预测 早期基于 BEV 的预测方法将过去的轨迹渲染为 BEV 图像,并使用 CNN 对光栅化输入进行编码,假设完美检测和跟踪物体。另一项工作是直接从 LiDAR 点云进行端到端轨迹预测。与实例级轨迹预测不同,MotionNet和 MP3 通过每个占用网格的运动(流)场来处理预测任务。与上述依赖 LiDAR 数据的方法相比,FIERY 首先仅根据多视图相机数据预测 BEV 实例分割。FIERY 按照 LSS 提取多帧 BEV 特征,使用循环网络将它们融合成时空状态,然后进行概率实例预测。StretchBEV 使用具有随机残差更新的随机时间模型改进了 FIERY。BVerse 提出了一种潜在空间中的迭代流扭曲,用于多任务 BEV 感知框架中的预测。这些方法遵循 Panoptic-DeepLab ,它利用四个不同的头来计算语义分割图、实例中心、每像素向心偏移和未来流。他们依靠复杂的后处理从这四种表示生成最终的实例预测。在本文中,我们表明只需两个头,即语义分割和向心向后流,再加上简化的后处理就足以用于未来的实例预测。 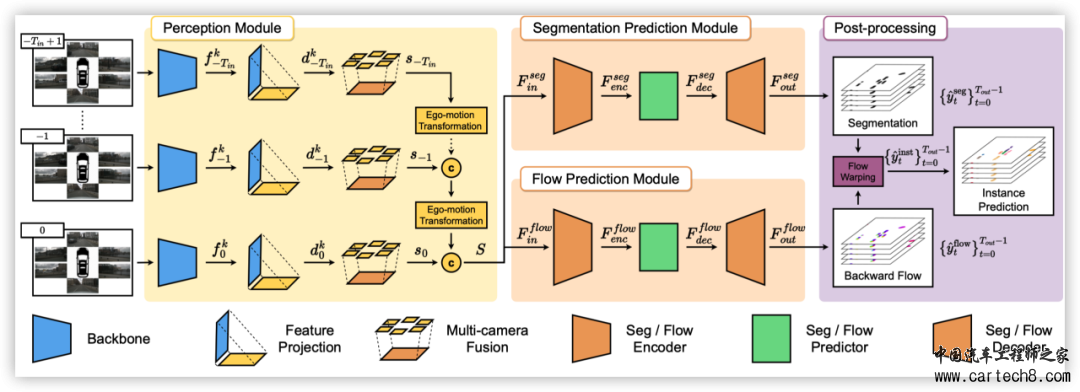 ▲图2|PowerBEV算法架构  在本节中,我们概述了我们提出的端到端框架。该方法的概述如图 2 所示。它由三个主要部分组成:感知模块、预测模块和后处理阶段。感知模块遵循 LSS ,并以时间戳中的 T 为输入,将 M 个多视图相机图像作为输入,并将它们提升到 BEV 特征图中的 T(参见第 3.1节)。然后,预测模块融合提取的 BEV 特征中包含的时空信息(参见第 3.2 节),并并行预测未来帧的分割图序列和向心向后流(参见第 3.3 节)。最后,从预测的分割中恢复未来的实例预测,并通过基于变形的后处理(参见第 3.4 节)。下面我们详细描述每个涉及的组件。 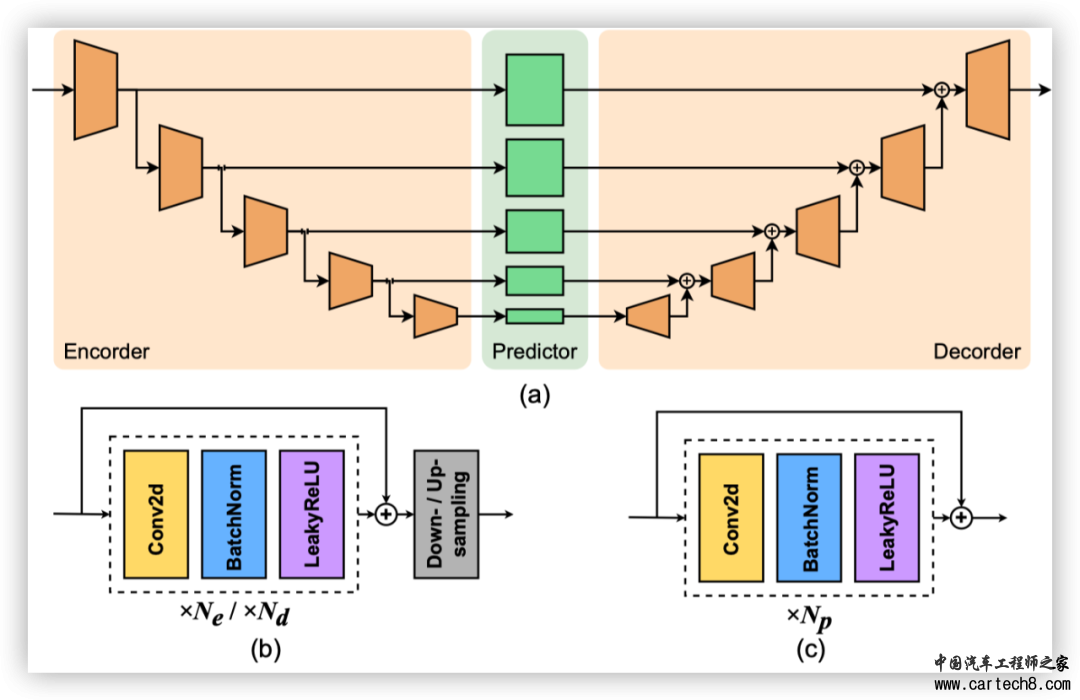 ▲图3|多尺度预测模型架构 ■4.1 基于LSS的感知模块 为了获得用于预测的视觉特征,本文遵循他人的工作并且在 LSS 上构建,从周围相机图像中提取 BEV 特征网格。更准确的,针对每张图像 |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论