纯视觉4D占用预测新基线 | Cam4DOcc:面向端到端一体化的纯视觉新方案
纯视觉4D占用预测新基线 | Cam4DOcc:面向端到端一体化的纯视觉新方案
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
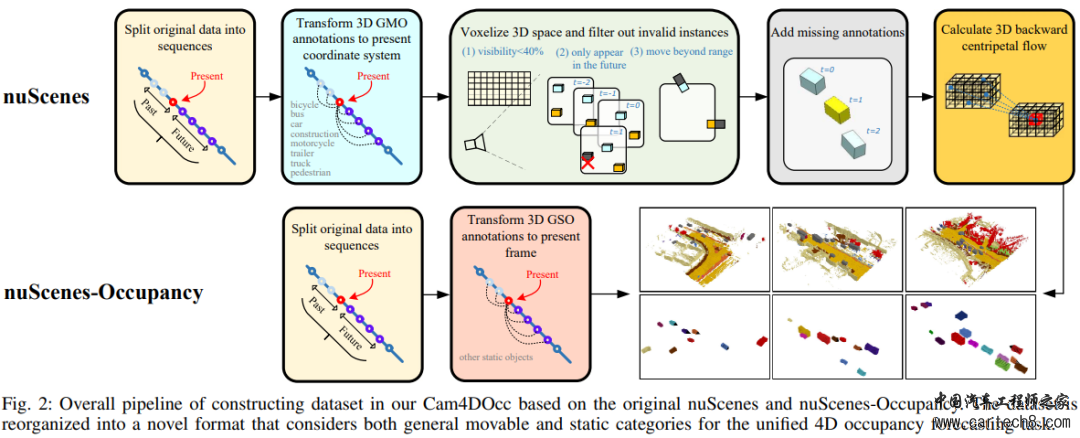
写在前面&笔者的个人理解刚出炉的Cam4DOcc,上交&国防科大&毫末联合出品!Cam4DOcc首先讨论了在自动驾驶中理解周围环境的重要性,以及目前依赖视觉图像的占用估计技术的局限性。进一步提出了Cam4Occ,这是一种用于纯视觉4D占用预测的新基准,用于评估在不久的将来周围场景的变化。为了全面比较本文的benchmark,Cam4Occ介绍了来自不同基于相机的感知和预测实现的四种基线类型,包括静态世界占用模型、点云预测的体素化、基于2D-3D实例的预测,以及本文提出的新的端到端4D占用预测网络(OCFNet)。代码即将开源! 比较新颖的部分
 其中^St和St分别表示时间戳t处的估计体素状态和真实体素状态,还提供了一个单一的定量指标来评估整个时间范围内的预测性能,使用一个值计算:  更接近当前时刻的时间戳IoU对最终IoUf的贡献更大。这符合近时间戳的占用预测对后续运动规划和决策更重要的原则
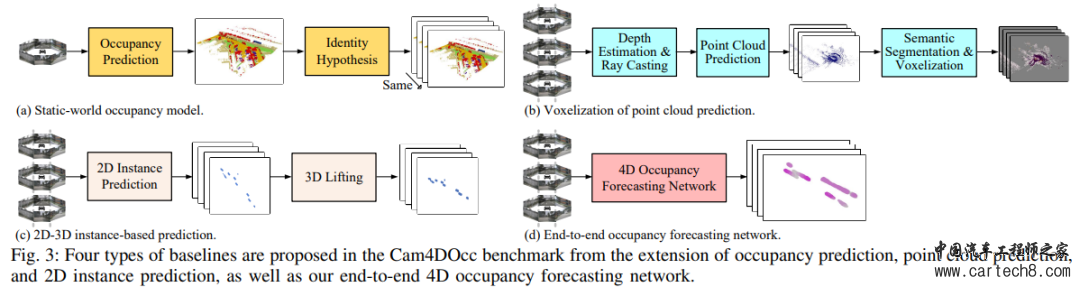 (1)静态世界占?模型:最直接的基线之?是假设环境在短时间内保持静态,因此,可以使?当前估计的占??格作为基于静态世界假设的所有未来时间步的预测,如图3a所?; (2)点云预测的体素化:使?环视深度估计来?成跨多个camera的深度图,然后通过光线投射来?成 3D 点云,将其与点云预测?起应?以获得预测的未来伪点,然后应用基于点的语义分割来获得每个体素的可移动和静态标签,从而产生最终的占用预测,如图3b所?; (3)基于 2D-3D 实例的预测:许多现成的基于BEV的2D实例预测方法可以用周围视图相机图像预测不久的将来的语义,第三种基线是通过将BEV生成的网格沿z轴复制到车辆的高度来获得3D空间中的预测GMO,如图3c所示,可以看出,该基线假设驾驶表面是平的,所有移动物体都具有相同的高度,我们不评估预测GSO的基线,因为与GMO相比,通过复制提高2D结果不适合模拟具有更复杂结构的大规模背景。 (4)端到端占?预测?络OCFNet:OCFNet 接收连续的过去环视camera图像来预测当前和未来的占?状态。它利?多帧特征聚合模块来提取扭曲的 3D 体素特征,并利?未来状态预测模块来预测未来的占?情况以及 3D 向后向心流,如图3d 所示。 端到端占?预测?络OCFNet(重点!!!):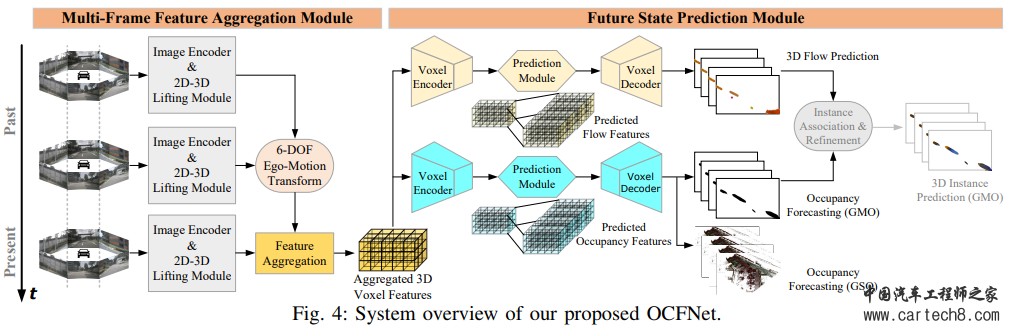 A.多帧特征聚合模块 多帧特征聚合模块以过去的环视相机图像为输入,采用图像编码器骨干提取二维特征。这些2D特征随后被2D-3D提升模块提升并集成到3D体素特征中。所有生成的3D特征体积都通过应用6自由度自我意识汽车姿势转换到当前坐标系,产生聚合特征:Fp ∈ R(Np+1)c×h×w×l,并将时间和特征维度折叠成一维以实现以下3D时空卷积,然后将与 6-DOF相关的ego-car相邻帧之间的姿势连接起来学习他的运动感知(这里笔者理解的就是物体运动姿态高度相关的连接起来,就大概直到了物体的运动方向,当然后续也假定认为是匀速运动): |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论