Tesla Auto Labeling方案分享
Tesla Auto Labeling方案分享
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
最近做了一段时间的Auto labeling,也跟很多人交流了对数据的看法。总的来说,大家看法还是一致的,数据很重要,对数据的理解也很重要。下面是我听到的两个印象深刻的观点: “ 扯远了,还是回到Tesla auto labeling。 两年前在重点关注他们的感知方案,现在则是重点关注Auto labeling方案,果然是屁股决定脑袋。 这段时间又断断续续看了好几遍,看的时候觉得很有收获,看完就忘了。记录一下,有兴趣的可以一起交流一下。 以下内容来源于tesla 2021 AI Day,2021 Andrej Karpathy CVPR分享,2022 AI Day三个视频,试图分析一下tesla的auto能力和技术演进方向,主要包括Auto labeling和Simulation两方面,下面将按照视频逐个解读。 2021 Andrej CVPR分享为了训练出一个好的神经网络,最先需要的是一个非常好的数据集,数据集有三个最重要的属性,large,clean,diverse。  举了两个实际的例子,车上掉碎片和大雪场景,看不清前方是否有车,来说明Tesla是如何通过Auto labeling来解决这两类问题的。 Tesla开发了221个rule based triggers,如下图所示。  Data Engine模块,由预设定的Trigger,挖掘出检测不好的场景。 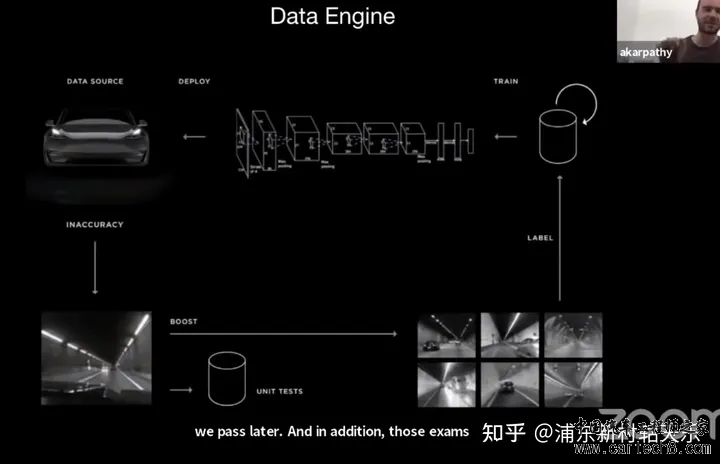 最终的数据集由7轮影子模式获得,包含100万个10s的video(强调高度不同的场景),60亿个object label。  最终发布之前,会跑6000个包含70种场景,人工挑选的有挑战的clips,10000个仿真场景等。  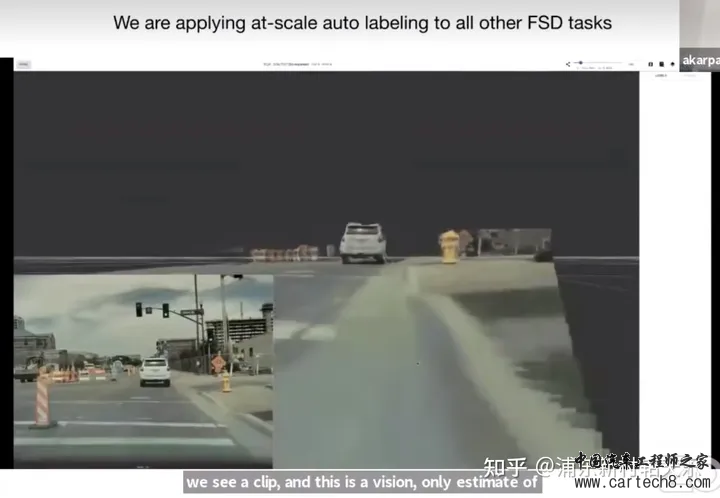 特斯拉2021人工智能日AI Day分人工标注、自动标注、Simulation和大规模数据产生4个部分来阐述。其中autolabeling部分是上文CVPR的扩展版,此处重点讲解Simulation部分。  Simulation的作用,产生如下3种场景的perfect label:很难找到的corner case,如图中高速上跑步的人;很难标注的场景,如拥挤的人群;, closed loop,闭环仿真?(没看懂)  为了提高仿真效果,Tesla做了如下5点:


 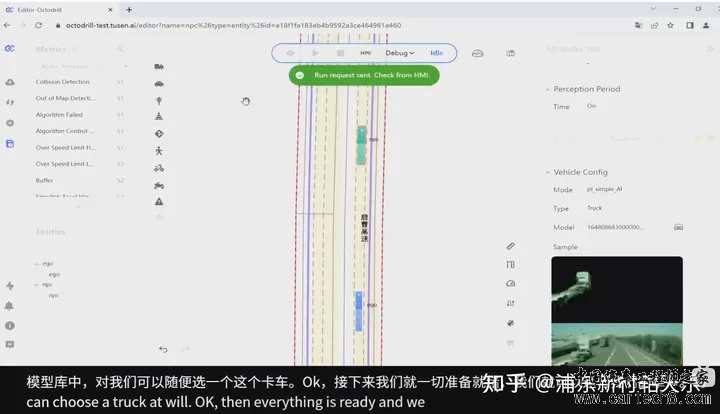

  Simulation真正发挥的作用:  2022 ai day在2022年的AI day上讲的方案,我认为最重要的两点是,海量数据,训练集和评测集都不断更新。 1 数据构成数据分为human label, auto label和simulation label。 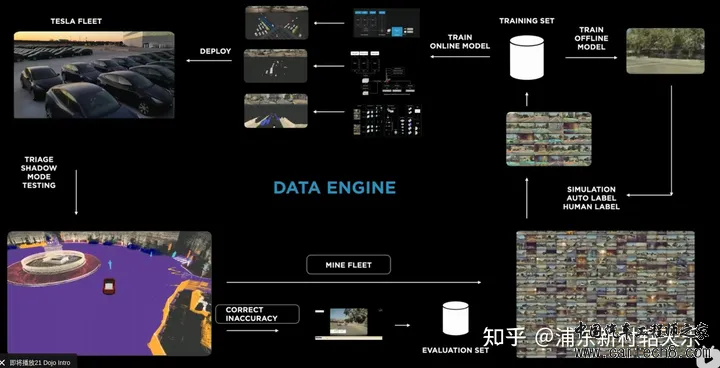 2 benchmark也会不断更新这跟我所了解的几家公司并不太一样,他们还常常是一个benchmark用上几年。 但由于benchmark的分布和真实一定是不一致的,如果benchmark不做更新,时间久了之后,很多工作都是在过拟合的优化,benchmark反应不出模型的性能变化,会变得不可信。 如下图是一个tesla通过数据挖掘来优化路边停止车辆运动状态检测不稳定造成的误刹车问题。其训练集、测试集是同时在更新的,检测精度是在稳步上升,这样才能真正反映出模型的性能提升。 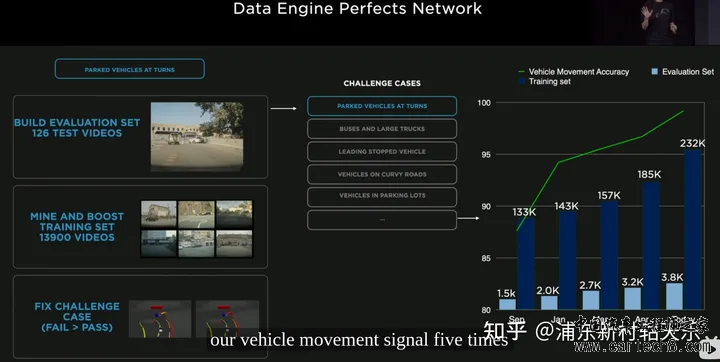 3 Lane的Auto labeling这里框图把训练数据分为了三块,Auto labeling, Simulation, Data Enigne 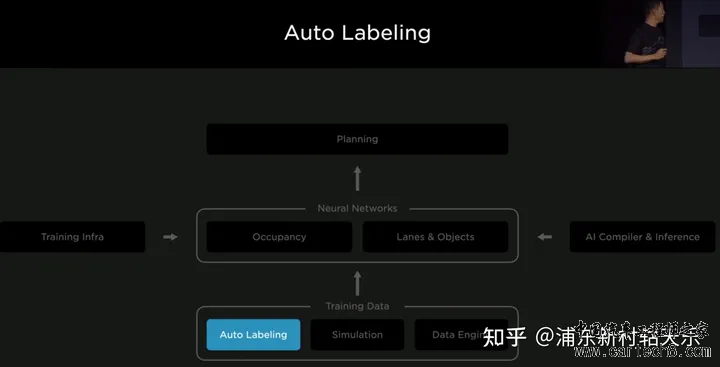 对于Lane,首先强调了自动标注的效率,对于10000次trip,人工500万小时,auto 12小时。 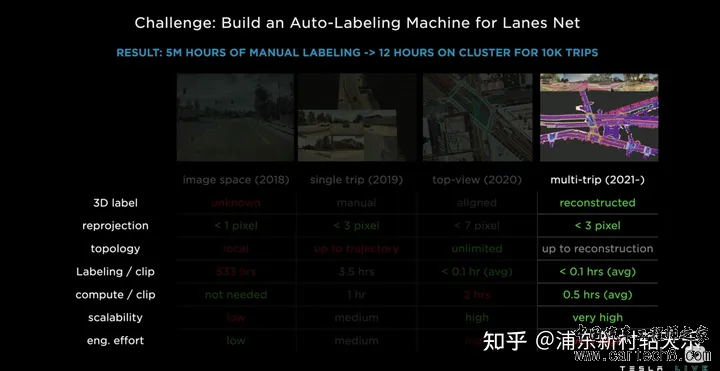 输入输出如下图所示   |
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论