特定人语音识别技术在汽车控制上的应用
以下为文章全文:(本站微信公共账号:cartech8)

汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
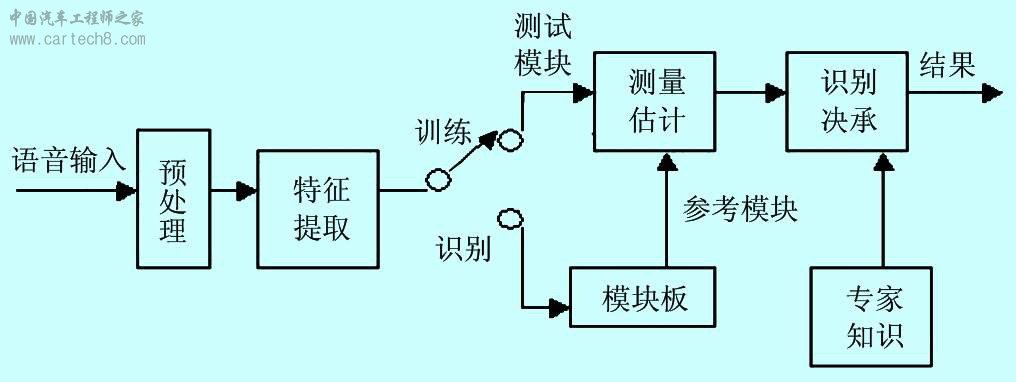
1 引言 从20世纪50年代开始对语音识别的研究开始,经过几十年的发展已经达到一定的高度,有的已经从实验室走向市场,如一些玩具、某些部门密码语音输入等,随着DSP和专用集成电路技术的发展,快速傅立叶变换以及近来嵌入式操作系统的研究,使得特定人识别尤其是计算量小的特定人识别成为可能。因此,对特定人语音识别技术在汽车控制上的应用的研究是很有前途的。 2 特定人语音识别的方法 目前,常用的说话人识别方法有模板匹配法、统计建模法、联接主义法(即人工神经网络实现)。考虑到数据量、实时性以及识别率的问题,笔者采用基于矢量量化和隐马尔可夫模型(HMM)相结合的方法。 说话人识别的系统主要由语音特征矢量提取单元(前端处理)、训练单元、识别单元和后处理单元组成,其系统构成如图1所示。
图1 系统构成 由上图也可以看出,每个司机在购买车后必须将自己的语音输入系统,也就是训练过程,当然最好是在安静、次数达到一定的数目。从此在以后驾驶过程中就可以利用这个系统了。 所谓预处理是指对语音信号的特 殊处理:预加重,分帧处理。预加重的目的是提升高频部分,使信号的频谱变得平坦,以便于进行频谱分析或声道参数分析。用具有 6dB/倍频程的提升高频特性的预加重数字滤波器实现。虽然语音信号是非平稳时变的,但是可以认为是局部短时平稳。故语音信号分析常分段或分帧来处理。 2.1 语音特征矢量提取单元 说话人识别系统设计中的根本问题是如何从语音信号中提取表征人的基本特征。即语音特征矢量的提取是整个说话人识别系统的基础,对说话人识别的错误拒绝率和错误接受率有着极其重要的影响。同语音识别不同,说话人识别利用的是语音信号中的说话人信息,而不考虑语音中的字词意思,它强调说话人的个性。因此,单一的语音特征矢量很难提高识别率。该系统在说话人的识别中采用倒谱系数加基因周期参数,而在对控制命令的语音识别中仅采用倒谱系数。其中,常用的倒谱系数有2 种,即LPC(线性预测系数)和倒谱参数(LPCC),一种是基于Mel刻度的MFLL(频率倒谱系数)参数(Mel频率谱系数)。 对于LPCC参数的提取, 可先采用Durbin递推算法、格型算法或者Schur递推算法来求LPC系数,然后求LPC参数。设第l帧语音的LPC系数为αn,则LPCC的参数为 其中p为LPCC系数的阶数,k为LPCC系数的递推次数。 进一步的研究发现,引入一阶和二阶差分倒谱可以提高识别率。 对于MPCC参数的提取,若根据Mel曲线将语音信号频谱分为K个频带,每个频带的能量为θ(Mk),则 MFCC参数为 通过对LPCC和MFCC参数对识别率影响的实验比较,笔者选取LPCC参数及其一阶和二阶差分倒谱稀疏作为特征参数。 基音周期估计的方法很多,主要有基于求短时自相关函数的算法、基于求短时平均幅度差函数(AMDF)的算法、基于同态信号处理和线性预测编码的算法。笔者仅介绍基于求短时自相关函数的算法。 设Sw(n)是一段加窗语音信号,它的非零区间为0<n≤n-1。Sw(n)的自相关函数称为语音信号的S(n)的短时自相关函数,用Rw(l)表示,即Rw(l)= 可知短时自相关函数在Rw(0)处最大,且在基音周期的各个整数倍点上有很大的峰值,选择合适的窗函数(窗长为40ms的Hamming窗)与滤波器(带宽为60~900Hz的带通滤波器)后,只要找到自相关函数的第一最大峰值点的位置并计算它与零点的距离,便能估计出基音周期。 2.2 训练单元 训练单元的功能是把事先收集到的语音利用一定的算法为每一个待识别的说话人训练出与之相匹配的参数。针对说话人识别在汽车应用中的不同的要求,训练单元也分为2部分:对说话人识别的训练和对待识别词的训练。 对于说话人识别部分的训练, 针对说话人的特征进行训练,为每个合法用户建立一套或多套HMM模型,同时采用基于矢量量化(VQ)的方法,为每个合法用户建立VQ码本。VQ码本的设计采用LBG算法,初始码本的设置采用分裂法初始码本。 第2 部分针对控制命令中用到的每个孤立的词条建立多个训练样本,或称为词条样本,估计出该词条的HMM参数(一套或多套)。对一个HMM过程的完整的描述包括:2个模型参数N和M,3组概率度量A,B和π。为了方便起见,通常采用如下方式表示一个完整的模型:λ=(N,M,π,A,B),或者简写为:λ= (π,A,B)。而对于每一个词条V的模型参数,V=1~V,可以用Baum-Welch重估算法。 |
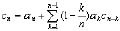 1<n≤p
1<n≤p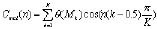 1<n≤p
1<n≤p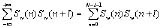
文章网友提供,仅供学习参考,版权为原作者所有,如侵犯到
你的权益请联系542334618@126.com,我们会及时处理。





会员评价:
共0条 发表评论